
爲什(shén)麽機器學習(xí)在投資領域不好使
發布時(shí)間:2017-04-05 | 來(lái)源: 川總寫量化(huà)
作者:石川
The essence of data snooping is that focusing on interesting events is quite different from trying to figure out which events are interesting.
1 引言
最近,一條新聞引爆了(le)投資圈:世界上最大(dà)的(de)投資管理(lǐ)公司貝萊德(BlackRock)宣布将使用(yòng)機器(确切的(de)說是人(rén)工智能 artificial intelligence 或機器學習(xí)算(suàn)法 machine learning algorithm)來(lái)取代一些基金經理(lǐ)進行選股。近年來(lái),随著(zhe)其在人(rén)臉識别,信用(yòng)反欺詐乃至國際象棋和(hé)圍棋領域的(de)應用(yòng)和(hé)傑出表現,人(rén)工智能被越來(lái)越多(duō)的(de)人(rén)所熟悉。很多(duō)人(rén)開始看好在不久的(de)将來(lái)機器學習(xí)算(suàn)法在二級市場(chǎng)投資上将會比人(rén)取得(de)更加優異的(de)成績。而貝萊德的(de)這(zhè)一宣布無疑将人(rén)工智能又一次推上了(le)風口浪尖。這(zhè)其中最根本的(de)觀點是:
機器學習(xí)通(tōng)過可(kě)以使用(yòng)複雜(zá)的(de)各種非線性算(suàn)法(比如神經網絡、決策樹、遺傳算(suàn)法)來(lái)從大(dà)量的(de)曆史交易數據中挖掘出人(rén)類無法看到的(de)投資模式。根據這(zhè)些模式來(lái)選股就可(kě)以取得(de)豐厚收益。
雖然身處并堅定地看好量化(huà)投資領域,但我對(duì)“機器學習(xí)在選股上能取代人(rén)類”這(zhè)個(gè)觀點上持保守和(hé)謹慎的(de)态度。這(zhè)是因爲金融分(fēn)析屬于非實驗性科學(nonexperimental science),因此無法進行對(duì)照(zhào)實驗(scientific control 或 controlled experiments)。這(zhè)意味著(zhe)雖然存在大(dà)量的(de)金融交易數據,但是無法通(tōng)過設計實驗來(lái)控制自變量的(de)變化(huà)、通(tōng)過重複性試驗來(lái)檢驗提出的(de)假設(比如說機器學習(xí)發現的(de)某種選股模式)。如此的(de)數據分(fēn)析得(de)到的(de)大(dà)多(duō)是看似顯著但實際上是欺騙式的(de)模式(尤其對(duì)樣本外數據),這(zhè)個(gè)現象稱作數據窺探(data snooping)。
數據窺探(data snooping):從數據中挖掘子虛烏有的(de)模式(finding patterns in the data that do not exist)。
數據窺探問題存在于所有的(de)非實驗性研究中,而當我們把複雜(zá)的(de)機器學習(xí)算(suàn)法用(yòng)于選股時(shí),這(zhè)種問題尤甚。這(zhè)是因爲複雜(zá)的(de)非線性算(suàn)法中包含大(dà)量的(de)參數,通(tōng)過這(zhè)些參數的(de)配合總能發現一些人(rén)類無法理(lǐ)解的(de)、可(kě)以獲得(de)超額收益的(de)選股模式。如果不能正确地理(lǐ)解并從業務上解釋這(zhè)些模式,數據窺探将使複雜(zá)的(de)機器學習(xí)算(suàn)法成爲從曆史數據中發現無效巧合的(de)高(gāo)效工具,正如本文開頭的(de)引用(yòng)所說的(de)那樣。
2 僞素數選股
來(lái)看一個(gè)和(hé)股票(piào)八竿子打不著(zhe)的(de)選股算(suàn)法。傳統的(de)基金經理(lǐ)恐怕絞盡腦(nǎo)汁也(yě)想不出這(zhè)麽個(gè)模式,但是機器學習(xí)算(suàn)法可(kě)以輕易地(但是錯誤地)找出它。這(zhè)個(gè)算(suàn)法利用(yòng)了(le)素數(質數)的(de)一個(gè)性質,它來(lái)自費馬小定理(lǐ)的(de)一個(gè)變種:除了(le) 2 之外,任何一個(gè)素數 x 滿足“2 的(de) x-1 次方被它自身除的(de)餘數爲 1”。
舉個(gè)例子,13 是一個(gè)素數,2 的(de) 13-1(即 12)次方等于 4096。用(yòng)它除以 13 得(de)到 315,餘數爲 1。可(kě)以證明(míng),所有 2 以外的(de)素數都滿足這(zhè)個(gè)性質。但是滿足這(zhè)個(gè)性質的(de)數不一定都是素數,它們被稱爲僞素數(又稱爲卡邁克爾數)。一萬以内的(de)僞素數有七個(gè):561,1105,1729,2465,2821,6601,以及 8911。我們利用(yòng)這(zhè)些僞素數來(lái)對(duì)美(měi)股進行選股:選擇股票(piào)編号中包含上述僞素數的(de)股票(piào)進行投資。按照(zhào)這(zhè)個(gè)規則,Ametek公司(一個(gè)制造企業,股票(piào)編号 03110510)脫穎而出。更令人(rén)稱奇的(de)是,它在過去 40 年取得(de)了(le) 95 倍的(de)累計收益,遠(yuǎn)超道瓊斯工業或标普 500 指數。
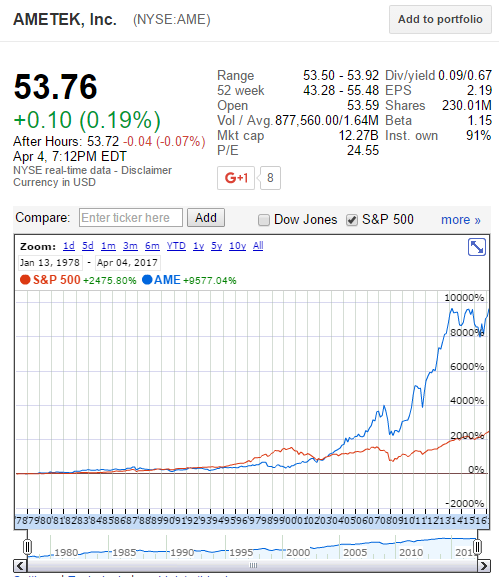
毫無疑問,這(zhè)是一支非凡的(de)股票(piào),而我們的(de)僞素數策略取得(de)了(le)巨大(dà)的(de)成功。然而, 先别急著(zhe)激動。我們需要好好審視一下(xià):僞素數和(hé)選股到底有什(shén)麽關系?答(dá)案是沒有關系。那麽這(zhè)個(gè)策略是否真正找到了(le)有效的(de)選股模式?答(dá)案也(yě)是否定的(de)。有些人(rén)會馬上跳出來(lái)說“隻要管用(yòng)就行,爲什(shén)麽有用(yòng)不重要!”。這(zhè)種認知是非常危險的(de)。對(duì)于選股這(zhè)種非實驗性問題,由于無法通(tōng)過對(duì)照(zhào)實驗來(lái)檢驗假設,那麽至少從業務上明(míng)白機器學習(xí)的(de)算(suàn)法爲什(shén)麽有效就顯得(de)格外重要。因此,“隻要管用(yòng)就行”是非常不負責任的(de)态度。
這(zhè)個(gè)例子代表了(le)很多(duō)機器學習(xí)算(suàn)法的(de)問題:我們總可(kě)以使用(yòng)複雜(zá)的(de)非線性算(suàn)法(比如神經網絡)、通(tōng)過過度優化(huà)參數發現回測中無敵的(de)選股模式。在這(zhè)個(gè)過程中,我們已然落入了(le)數據窺探陷阱。
3 認知偏差加劇數據窺探
在以下(xià)這(zhè)些條件下(xià)很容易發生數據窺探問題,很顯然它們都存在于二級市場(chǎng)投資中:
1. 存在大(dà)量的(de)數據。
2. 很多(duō)人(rén)都在使用(yòng)同樣的(de)數據進行分(fēn)析。
3. 缺乏業務理(lǐ)論或者無法控制變量。
4. 認知偏差“隻要管用(yòng)就行,爲什(shén)麽好使不重要”。
這(zhè)其中前三條是市場(chǎng)的(de)客觀條件,而最後一條則植根于人(rén)們的(de)認知錯誤。人(rén)類認知中總是傾向于追尋不同尋常的(de)事件。隻有當一些“不同尋常”的(de)巧合發生時(shí),我們才往往能關注到。瑞士心理(lǐ)學家榮格将人(rén)們對(duì)巧合的(de)過度關注稱爲共時(shí)性(synchronicity)。
共時(shí)性:指“有意義的(de)巧合”,用(yòng)于解釋因果律無法解釋的(de)現象,如夢境成真,想到某人(rén)某人(rén)便出現等(“說曹操、曹操到”)。榮格認爲,這(zhè)些表面上無因果關系的(de)事件之間有著(zhe)非因果性、有意義的(de)聯系,這(zhè)些聯系常取決于人(rén)的(de)主觀經驗。當兩者同時(shí)發生時(shí),便稱爲“共時(shí)性”現象。
通(tōng)俗的(de)說,當在時(shí)間和(hé)空間上毫無聯系的(de)兩件事同時(shí)發生時(shí),人(rén)們便會認爲有一種超自然的(de)神秘力量把它們聯系在一起,并認爲這(zhè)種巧合具備某種意義。比如在上面的(de)例子中,股票(piào)标碼含有僞素數和(hé)股票(piào)獲得(de)了(le)巨大(dà)的(de)超額收益就是一個(gè)純粹的(de)巧合,這(zhè)樣的(de)巧合被機器學習(xí)算(suàn)法發現并呈現給使用(yòng)者。如果使用(yòng)者不試圖去理(lǐ)解這(zhè)兩者到底是否真的(de)有關系,便會由于共時(shí)性而将這(zhè)種錯誤的(de)巧合賦予某種意義,即機器學習(xí)發現了(le)一個(gè)牛逼哄哄的(de)選股模式。
4 運氣還(hái)是實力
前面說了(le)這(zhè)麽多(duō),目的(de)當然不是爲了(le)否定人(rén)工智能和(hé)機器學習(xí)在二級市場(chǎng)的(de)應用(yòng)前景。但我想說,對(duì)于人(rén)工智能發現的(de)任何模式,它有效的(de)前提是我們能夠明(míng)白無誤的(de)理(lǐ)解它的(de)含義。不能以此爲基礎便無法分(fēn)辨出好的(de)結果到底是來(lái)自運氣還(hái)是實力。之前,我寫過一篇文章(zhāng)《出色不如走運?》。文中使用(yòng)順序統計量(order statistic)解釋了(le)這(zhè)樣一個(gè)道理(lǐ):
在衆多(duō)股票(piào)中,最好的(de)那支總會有非常優秀的(de)收益率;在衆多(duō)的(de)策略中,最厲害的(de)那一個(gè)總會帶來(lái)令人(rén)稱奇的(de)回報率。然而,通(tōng)過計算(suàn)獨立樣本的(de)極值(順序統計量)分(fēn)布可(kě)知,這(zhè)種結果實屬必然。
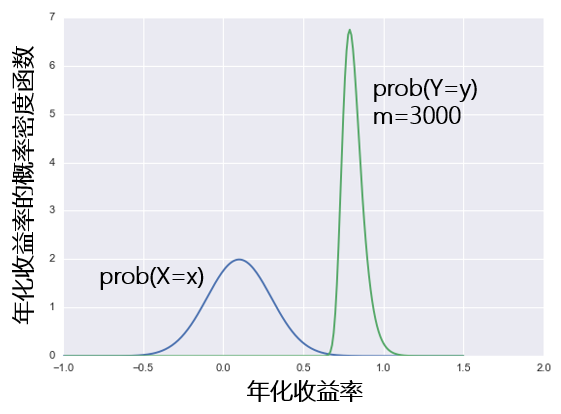
我們回顧一下(xià)那篇文章(zhāng)中的(de)例子。假設一個(gè)股票(piào)投資策略的(de)年化(huà)收益率 X 符合均值爲 10%,标準差爲 20% 的(de)正态分(fēn)布。假設市場(chǎng)中有 m 個(gè)不同的(de)策略,則它們中最好的(de)那個(gè)的(de)收益率 Y 是 X 的(de)函數,Y = max(X1, X2, …, Xm)。下(xià)圖是當 m = 3000 時(shí),最好的(de)那個(gè)的(de)收益率分(fēn)布和(hé)單一策略收益率分(fēn)布的(de)比較:最優策略的(de)收益率分(fēn)布在橫坐(zuò)标上向右移動且變的(de)更窄。
下(xià)圖爲 prob(Y≥0.7) 随策略個(gè)數 m 變化(huà)的(de)結果。同時(shí)也(yě)給出了(le) Y 的(de)均值和(hé)标準差随 m 的(de)變化(huà)。随著(zhe) m 的(de)增大(dà),我們越來(lái)越确定總會有一些策略脫穎而出,年化(huà)收益率超過 70%。這(zhè)種判斷也(yě)同樣可(kě)以被 Y 的(de)均值和(hé)方差來(lái)證明(míng):随著(zhe)策略個(gè)數的(de)增大(dà),最優策略的(de)年化(huà)收益率的(de)均值在增加,且标準差在減小。
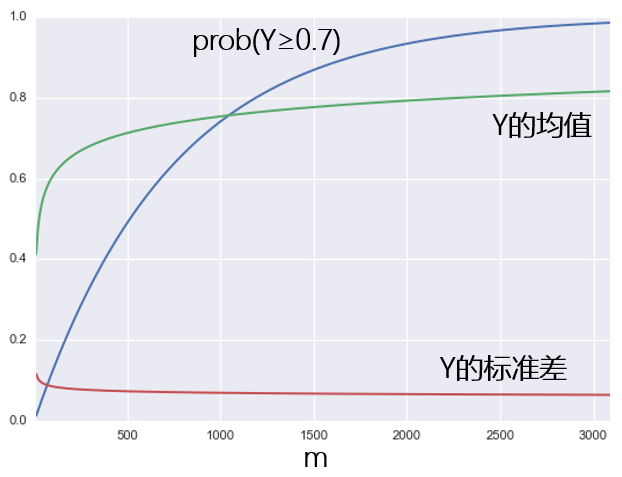
這(zhè)個(gè)結果說明(míng),當存在大(dà)量不同的(de)策略時(shí),最好的(de)那一個(gè)總會異常非凡。但我們真正關心的(de)問題是:這(zhè)個(gè)策略到底是在茫茫曆史數據中找到了(le)虛假的(de)模式,還(hái)是發現了(le)一套真正的(de)科學投資模式?我們必須從業務層面弄清楚它是如何工作的(de)。
5 前路漫漫
其實,人(rén)們使用(yòng)算(suàn)法來(lái)選股并不是什(shén)麽新鮮事。風險多(duō)因子模型就可(kě)以算(suàn)是一個(gè)算(suàn)法選股的(de)策略。當然,它之所以有效是因爲它使用(yòng)的(de)因子,比如成長(cháng)因子、規模因子、動量因子等,都有著(zhe)清晰的(de)業務基礎。近幾年,很多(duō)人(rén)使用(yòng)機器學習(xí)的(de)複雜(zá)算(suàn)法,比如支持向量機,來(lái)改進多(duō)因子選股。這(zhè)些非線性算(suàn)法構建了(le)很多(duō)非線性的(de)因子。比如,如果算(suàn)法告訴我們“雄安概念闆塊,且對(duì)數市值 ÷ 三個(gè)月(yuè)動量大(dà)于 π”是一個(gè)好的(de)模式,那我們就得(de)好好琢磨琢磨了(le)。
對(duì)于人(rén)工智能在二級市場(chǎng)投資的(de)應用(yòng),一位具有豐富實戰經驗的(de)量化(huà)投資前輩闡述過如下(xià)的(de)觀點,我對(duì)此十分(fēn)認可(kě):
我們可(kě)以相信它(人(rén)工智能)能夠捕獲到那些人(rén)類根本無法察覺到的(de)細微模式。但是,這(zhè)些模式能夠持續嗎?這(zhè)些模式會不會隻是一些不會重複的(de)随機噪聲?人(rén)工智能領域的(de)專家向我們保證他(tā)們有許多(duō)防範措施用(yòng)以過濾那些瞬間噪聲。并且,這(zhè)些工具确實在消費者營銷和(hé)信用(yòng)卡欺詐檢測上效果顯著。消費者行爲和(hé)詐騙行爲的(de)模式顯然都具有較長(cháng)的(de)持續期,這(zhè)使得(de)這(zhè)些人(rén)工智能算(suàn)法即使包含大(dà)量參數也(yě)能有效運行。然而,以我的(de)經驗來(lái)看,要對(duì)金融市場(chǎng)進行預測,這(zhè)種防範措施是遠(yuǎn)遠(yuǎn)不夠的(de),并且對(duì)曆史數據噪聲的(de)過度拟合還(hái)會帶來(lái)嚴重後果。……相對(duì)于可(kě)以獲取的(de)大(dà)量相互獨立的(de)消費者行爲和(hé)信用(yòng)交易數據,我們能夠獲取的(de)在統計學意義上相互獨立的(de)金融數據是非常有限的(de)。你可(kě)能會說,我們擁有大(dà)量分(fēn)時(shí)金融數據可(kě)供使用(yòng)。但實際上,這(zhè)些數據是序列相關的(de),并不是相互獨立的(de)。
這(zhè)位前輩對(duì)于人(rén)工智能何時(shí)有效給出了(le)自己的(de)見解:
1. 基于正确的(de)計量經濟學或理(lǐ)論基礎,而不是随機發現的(de)模式。
2. 所需的(de)參數用(yòng)到曆史數據較少。
3. 隻用(yòng)到線性回歸,并未使用(yòng)複雜(zá)的(de)非線性函數。
4. 概念上很簡單。
5. 所有優化(huà)都必須在不含未來(lái)未知數據的(de)移動窗(chuāng)口中實現,并且這(zhè)種優化(huà)的(de)效果必須不斷地被未來(lái)未知的(de)數據所證實。
策略的(de)規則越多(duō),模型的(de)參數越多(duō),就越有可(kě)能發生數據窺探。能經得(de)起時(shí)間考驗的(de)往往是簡單的(de)模型。
6 再看貝萊德的(de)決定
作爲全球最大(dà)的(de)資産管理(lǐ)公司,貝萊德宣布使用(yòng)人(rén)工智能代替基金經理(lǐ)無法令人(rén)忽視,且必然會一石激起千層浪。有機構預測,到 2025 年,全球金融機構将有 10% 的(de)人(rén)工會被機器取代。這(zhè)恐怕和(hé)越來(lái)越高(gāo)昂的(de) alpha 不無關系。畢竟,從長(cháng)期來(lái)看,絕大(dà)多(duō)數基金經理(lǐ)都跑不赢指數,那麽要這(zhè)些基金經理(lǐ)還(hái)有什(shén)麽用(yòng)呢(ne)?
引用(yòng)我的(de)合夥人(rén)高(gāo)老闆的(de)話(huà)也(yě)許可(kě)以更好的(de)理(lǐ)解貝萊德的(de)這(zhè)個(gè)決定:
超額收益越來(lái)越貴,開源不行,就想辦法節流。最終投資市場(chǎng)的(de)均衡狀态是超額收益的(de)邊際成本恰好等于超額收益。這(zhè)樣成本高(gāo)的(de)投資基金終将不斷被成本低的(de)基金擠出市場(chǎng)。
免責聲明(míng):入市有風險,投資需謹慎。在任何情況下(xià),本文的(de)内容、信息及數據或所表述的(de)意見并不構成對(duì)任何人(rén)的(de)投資建議(yì)。在任何情況下(xià),本文作者及所屬機構不對(duì)任何人(rén)因使用(yòng)本文的(de)任何内容所引緻的(de)任何損失負任何責任。除特别說明(míng)外,文中圖表均直接或間接來(lái)自于相應論文,僅爲介紹之用(yòng),版權歸原作者和(hé)期刊所有。