
寫給你的(de)金融時(shí)間序列分(fēn)析:回歸篇
發布時(shí)間:2024-06-04 | 來(lái)源: 川總寫量化(huà)
作者:石川
摘要:時(shí)間序列回歸分(fēn)析并非是簡單地将兩個(gè)序列進行回歸處理(lǐ),而是一個(gè)需要精心設計和(hé)仔細考量的(de)過程,每一步都涉及到對(duì)數據特性的(de)深入理(lǐ)解和(hé)對(duì)模型假設的(de)嚴格檢驗。
0 引言
本文繼續拓展《寫給你的(de)時(shí)間序列分(fēn)析》系列。系列的(de)前序文章(zhāng)《寫給你的(de)金融時(shí)間序列分(fēn)析:基礎篇》、《寫給你的(de)金融時(shí)間序列分(fēn)析:初級篇》、《寫給你的(de)金融時(shí)間序列分(fēn)析:進階篇》、《寫給你的(de)金融時(shí)間序列分(fēn)析:應用(yòng)篇》和(hé)《寫給你的(de)金融時(shí)間序列分(fēn)析:補完篇》主要是針對(duì)單一時(shí)間序列的(de)檢驗和(hé)建模。本文則介紹多(duō)個(gè)時(shí)間序列之間的(de)回歸問題。
在時(shí)序回歸模型中,最簡單的(de)模型是靜态模型(static model):
在該模型中,“靜态”意味著(zhe)模型考察的(de)是
式中
不同于截面回歸,時(shí)序回歸的(de)難點在于各種(自、協)相關性的(de)處理(lǐ):包括解釋變量的(de)自相關性、随機擾動(error)的(de)自相關性;前、後不同期解釋變量和(hé) error 的(de)協相關性等。因此,在通(tōng)過回歸來(lái)分(fēn)析時(shí)間序列時(shí)需要格外小心,避免得(de)到錯誤的(de)統計推斷結果。本文的(de)主要内容包括,有限樣本下(xià) OLS 估計量的(de)性質、大(dà)樣本下(xià) OLS 估計量的(de)漸近性質、error 自相關性檢驗和(hé)應對(duì)、error 異方差性問題、僞回歸、協整及其推斷以及誤差修正模型。本文的(de) technique 部分(fēn)主要參考了(le) Wooldridge 的(de)神書(shū) Introductory Econometrics: A Modern Approach,特此說明(míng)。
1 Finite Sample Properties of OLS
在有限樣本下(xià),OLS 的(de)核心假設包括:
假設一(Linear in parameters):總體中
和(hé) 滿足線性關系。 假設二(No perfect collinearity):解釋變量之間不存在完美(měi)的(de)共線性。
假設三(Zero conditional mean):
。這(zhè)意味著(zhe)所有解釋變量都是外生的(de),即任何解釋變量,在任何時(shí)刻都和(hé) 不相關。
爲了(le)加強理(lǐ)解,我們再對(duì)假設三做(zuò)一些說明(míng)。首先,這(zhè)個(gè)假設中最重要的(de)就是
除上述三條假設外,再考察下(xià)面兩個(gè)假設:
假設四(Homoskedasticity):同方差,即
假設五(No serial correlation):
。這(zhè)條假設是關于 error 自相關性的(de)。它對(duì)解釋變量的(de)自相關性不做(zuò)任何假設。(解釋變量存在自相關性也(yě)是時(shí)序回歸模型的(de)特點之一。)
上述五條假設正是時(shí)序回歸模型的(de) Gauss-Markov 假設。當這(zhè)些假設均成立時(shí),
其中
其中
2 Asymptotic Properties of OLS
2.1 平穩性和(hé)弱相關性
對(duì)于絕大(dà)多(duō)數實際問題而言,前一節的(de) Gauss-Markov 假設都太嚴苛了(le),難以滿足(特别是解釋變量嚴格外生)。因此,比起考察有限樣本下(xià) OLS 估計量的(de)特性外,我們自然更關心在大(dà)樣本下(xià) OLS 估計量的(de)漸近性質。不過諷刺的(de)是,對(duì)于時(shí)序回歸模型而言,我們往往很難有足夠多(duō)的(de)樣本。(比如用(yòng)月(yuè)頻(pín)收益率數據檢驗一個(gè)多(duō)因子模型,那麽每年才有 12 個(gè)樣本,50 年也(yě)才有 600 個(gè)樣本。)不幸的(de)是,時(shí)序問題的(de)大(dà)樣本分(fēn)析比截面數據分(fēn)析複雜(zá)得(de)多(duō)。我們需要格外小心數據的(de)相關性。爲此,我們首先來(lái)回顧平穩性和(hé)弱相關性的(de)概念。
如果随機過程
對(duì)于一個(gè)平穩序列,如果
2.2 漸近性質
一旦平穩性和(hé)弱相關性得(de)到滿足,大(dà)數定律和(hé)中心極限定理(lǐ)就可(kě)以适用(yòng),因此在大(dà)樣本下(xià)可(kě)以獲得(de) OLS 估計量的(de)一些良好性質,從而幫助分(fēn)析
假設一(Linear in parameters):這(zhè)一條和(hé)前一節中的(de)假設一相同。除此之外,我們假設
滿足平穩性和(hé)弱相關性。 假設二(No perfect collinearity):解釋變量之間不存在完美(měi)的(de)共線性。
假設三(Zero conditional mean):
。相比于前一節中的(de)假設三,此處把它放松到 期 和(hé)解釋變量 的(de)獨立性了(le)。相比于嚴格外生,這(zhè)一條要弱很多(duō),隻限制同時(shí)期的(de)相關性,而對(duì)于 和(hé)任何非 時(shí)刻的(de)解釋變量之間的(de)關系不做(zuò)任何限制。當平穩性滿足時(shí),如果 對(duì)某一期 成立,則它對(duì)所有的(de) 都成立。然而,這(zhè)條假設下(xià)允許 期的(de) 影(yǐng)響未來(lái)的(de)解釋變量 。
當以上三條假設均滿足時(shí),OLS 估計量是一緻的(de),即
接下(xià)來(lái),和(hé)本文第 1 節一樣,再加上假設四和(hé)假設五:
假設四(Homoskedasticity):同方差,即
假設五(No serial correlation):
。
當上述五個(gè)假設都滿足時(shí),OLS 估計量在大(dà)樣本下(xià)表現出很好的(de)漸近性質:(1)OLS 估計量滿足漸近正态分(fēn)布;(2)所有相關的(de) t-statistic 和(hé) F-statistic 都是漸近成立的(de);(3)OLS 是漸近有效的(de),即它的(de)方差相比于其他(tā) estimators 的(de)方差更低。
3 Error Serial Correlation
由以上介紹可(kě)知,error 存在自相關并不影(yǐng)響 OLS 估計量的(de)無偏性。然而,它會影(yǐng)響
3.1 自相關性檢驗
一般來(lái)說,我們可(kě)以檢驗 error 是否滿足 AR(1) 過程。此時(shí),取決于解釋變量是否嚴格外生,又分(fēn)爲兩種情況。首先假設解釋變量嚴格外生,則可(kě)以通(tōng)過如下(xià)的(de)步驟檢驗:
Step 1: 用(yòng)
對(duì) 時(shí)序回歸,得(de)到殘差序列 。 Step 2: 用(yòng)
對(duì) 時(shí)序回歸,即 。 Step 3: 考察回歸系數
的(de) t-statistic,并進行統計推斷。如果拒絕原假設 ,則說明(míng) error 存在自相關性。
值得(de)一提的(de)是,上述第二步中的(de)自回歸模型中假設了(le)
除了(le)上述方法外,另一個(gè)常見的(de)檢驗是 Durbin-Watson Test(DW Test,比如 Python 的(de) OLS 回歸結果會返回 DW test 的(de)值)。該統計量爲:
通(tōng)常情況下(xià),
接下(xià)來(lái)看看解釋變量不是完全外生的(de)情況。在這(zhè)種情況下(xià),上述檢驗不再有效(及時(shí)在大(dà)樣本下(xià)也(yě)是如此),因此不能使用(yòng)。此時(shí),可(kě)以将上述三步走中的(de)第二步改爲如下(xià)的(de)回歸模型:
即使用(yòng)
然後,可(kě)以使用(yòng) F test 檢驗
3.2 修正 Error 自相關性
如果 error 存在在相關性,我們可(kě)以對(duì)它進行處理(lǐ)。假設 error 是一個(gè) AR(1) 過程且
由上述模型可(kě)知
上述變形後得(de)到的(de)估計量爲 GLS 估計量,它是 BLUE,因此 t test 和(hé) F test 都可(kě)以正常使用(yòng)。GLS 估計量中假設
Step 1: 用(yòng)
對(duì) 時(shí)序回歸,得(de)到殘差序列 。 Step 2: 用(yòng)
對(duì) 時(shí)序回歸,即 。 Step 3: 考慮如下(xià)回歸模型(注意:該模型沒有截距項):
其中 ; ; ; ; ; 。
在這(zhè)個(gè)回歸模型中,t test 和(hé) F test 都在大(dà)樣本下(xià)是漸近有效。上述的(de)模型看上去如此複雜(zá)是因爲
無論
3.3 Serial Correlation-Robust Inference for OLS
考慮如下(xià)時(shí)序回歸模型:
爲了(le)方便討(tǎo)論,假設我們關注
Step 1:進行 OLS 回歸,得(de)到
的(de) standard error,記爲“ ”,同時(shí)得(de)到 以及殘差序列 。 Step 2:以
爲被解釋變量(因爲我們關心的(de)是 ),以其他(tā) 爲自變量,構造如下(xià)回歸模型: Step 3:利用(yòng) OLS 得(de)到殘差序列
。用(yòng)該序列和(hé) 序列相乘得(de)到新的(de)序列
Step 4:選定希望考慮的(de)自相關 lags
,計算(suàn)變量 (有沒有想起 Newey-West):
Step 5:使用(yòng)以下(xià)公式得(de)到
的(de) serial correlation-robust standard error:
通(tōng)常情況下(xià),如果 error 确實存在自相關性,那麽上述得(de)到的(de) standard error 會大(dà)于 OLS 的(de) standard error。當 error 自相關非常嚴重時(shí),使用(yòng)上述方法得(de)到的(de) standard error 往往非常大(dà),導緻回歸系數不再顯著。在實踐中,如果能夠合理(lǐ)的(de)認爲解釋變量是完全外生的(de)話(huà),則建議(yì)使用(yòng) FGLS;反之,如果我們對(duì)解釋變量的(de)外生性存在非常強烈的(de)疑問時(shí),可(kě)以選擇 OLS + serial correlation-robust standard error。
4 Heteroskedasticity
異方差意味著(zhe) error 的(de)波動随
Breusch-Pagan test 的(de)步驟總結如下(xià):
Step 1:通(tōng)過 OLS 來(lái)估計原始回歸模型,得(de)到殘差序列
: Step 2:使用(yòng)
作爲被解釋變量,并考慮如下(xià)回歸模型,計算(suàn)其 R-squared,記爲 : Step 3:構建 F-statistic 或 LM-statistic 如下(xià):
Step 4:根據 F-statistic 或 LM-statistic 判斷是否拒絕原假設(原假設是沒有異方差)。如果存在異方差,那麽它雖然不會影(yǐng)響回歸系數的(de)無偏性,但是會影(yǐng)響 standard errors,因此應使用(yòng) heteroskedasticity-robust standard errors。
5 僞回歸
5.1 I(1) 序列
從上面的(de)論述可(kě)知,大(dà)樣本下(xià) OLS 滿足良好漸近性質的(de)關鍵條件是時(shí)間序列滿足平穩性和(hé)弱相關性。對(duì)于有些時(shí)間序列,其前後滿足強相關性(比如股票(piào)價格),這(zhè)時(shí)就應該進行必要的(de)處理(lǐ)。不滿足弱相關性的(de)一個(gè)例子正是随機遊走(Random Walk):
随機遊走是一個(gè)特殊的(de) unit root process。更一般的(de)情況中,
滿足弱相關性的(de)時(shí)間序列是
5.2 僞回歸
如果貿然對(duì)兩個(gè)
來(lái)看下(xià)面這(zhè)個(gè)例子。假設
其中
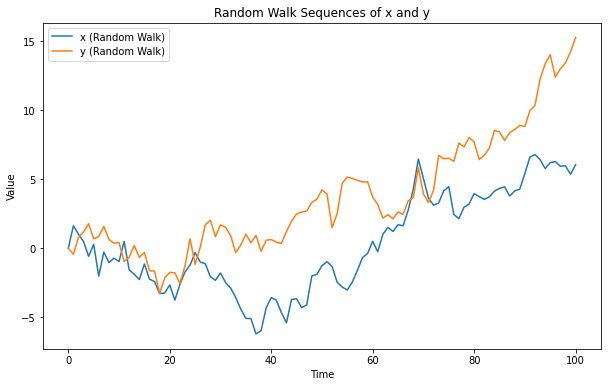
然而事實是,by design 這(zhè)兩個(gè)序列之間是相互獨立的(de)。那麽,下(xià)面這(zhè)種解釋有沒有可(kě)能:“由于噪聲,這(zhè)兩個(gè)序列之間相互獨立或許是假設檢驗中的(de)小概率事件”?如果這(zhè)個(gè)解釋成立,那麽如果我們進行大(dà)量的(de)随機模拟,并以 2.0 作爲 t-statistic 絕對(duì)值的(de)阈值,那麽應該僅在 5% 的(de)随機模拟中看到兩者的(de)相關性。不幸的(de)是,模拟結果否決了(le)上述猜想。在模拟的(de) 500 次實驗中,t-statistic 絕對(duì)值超過 2.0 的(de)情況出現比例超過 70%(下(xià)圖展示了(le) t-statistic 絕對(duì)值的(de)分(fēn)布)顯然,回歸模型所發現的(de)二者之間的(de)關系是虛假的(de)。這(zhè)個(gè)現象最初被 Granger and Newbold (1974) 發現,他(tā)們将其稱爲僞回歸。
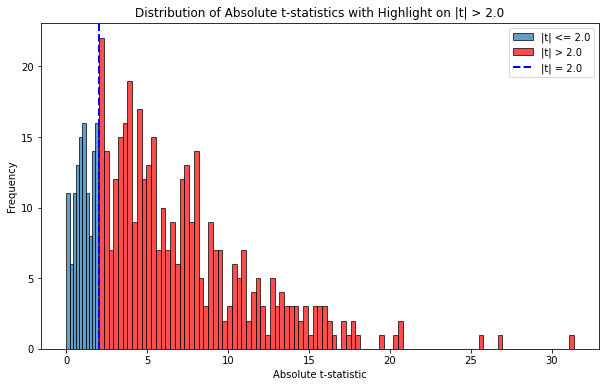
當我們用(yòng)
這(zhè)個(gè)例子說明(míng),在進行回歸分(fēn)析之前,應該首先檢驗時(shí)間序列是否滿足平穩性。爲此,可(kě)以考慮使用(yòng) Augmented Dickey-Fuller test。對(duì)于給定的(de)時(shí)間序列,例如
在上式中,如果時(shí)間序列
6 Cointegration
6.1 Cointegration
考慮兩個(gè)
當協整發生時(shí),這(zhè)兩個(gè)序列的(de)随機過程能夠抵消掉的(de)原因是它們共享某個(gè)共同的(de)長(cháng)期趨勢(共同的(de)因素)。在這(zhè)種情況下(xià),兩個(gè)序列才可(kě)能發生協整、它們的(de)線性組合才能滿足平穩性。協整關系的(de)重要性在于它允許人(rén)們使用(yòng)非平穩數據進行回歸分(fēn)析,同時(shí)獲得(de)有意義的(de)經濟解釋和(hé)預測。當我們有兩個(gè)序列時(shí),可(kě)以通(tōng)過 Engle-Granger 兩步檢驗來(lái)檢驗協整;而當研究對(duì)象爲多(duō)個(gè)時(shí)間序列時(shí),則可(kě)以使用(yòng) Johansen 檢驗。爲了(le)簡單起見,以下(xià)通(tōng)過一個(gè)例子介紹 Engle-Granger test。
6.2 Engle-Granger Test
對(duì)于兩個(gè)
Step 1:用(yòng)
對(duì) 回歸: ,并得(de)到殘差 。 Step 2:對(duì)殘差
進行“ADF”檢驗,考察其是否滿足平穩性。這(zhè)裏之所以在 ADF 上加引号,是因爲原始 ADF 是檢驗單一時(shí)間序列是否滿足平穩性的(de),而此處我們的(de) 是兩個(gè) 回歸的(de)殘差,因此在檢驗 時(shí)使用(yòng)的(de)檢驗統計量的(de) critical values 和(hé)一般的(de) ADF 檢驗稍有區(qū)别。爲此,應該使用(yòng) Phillips and Ouliaris (1990) 給出的(de) critical values。
下(xià)面就用(yòng)一個(gè)例子來(lái)介紹一下(xià)。我們研究的(de)對(duì)象是 AUDUSD 和(hé) NZDUSD 這(zhè)兩個(gè) forex rates,前者是澳大(dà)利亞元對(duì)美(měi)元的(de)彙率,後者是是新西蘭元對(duì)美(měi)元的(de)彙率。首先,我們使用(yòng) ADF 檢驗來(lái)确認這(zhè)兩個(gè)時(shí)間序列本身都是
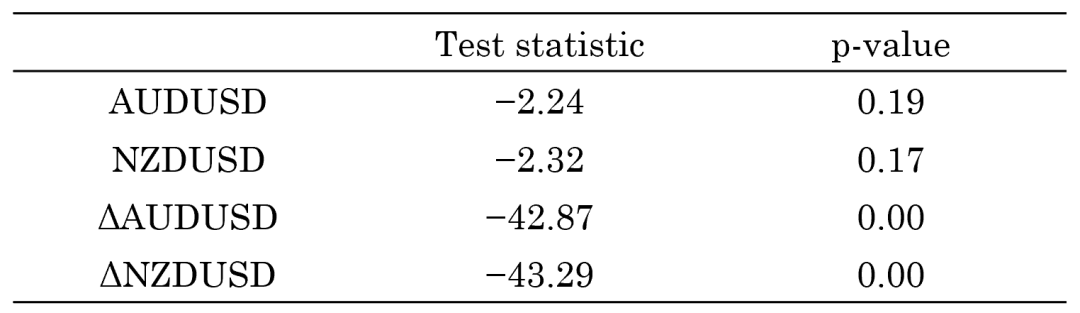
接下(xià)來(lái),進行 Engle-Granger Test。結果顯示,回歸模型的(de)殘差的(de) ADF 檢驗拒絕了(le)原假設(p-value = 0.018),意味著(zhe)殘差滿足平穩性,因此 AUDUSD 和(hé) NZDUSD 協整。通(tōng)過繪制殘差(下(xià)圖),我們也(yě)确實可(kě)以看到,它在一定的(de)區(qū)間内平穩運行,呈現出均值回複的(de)特性。
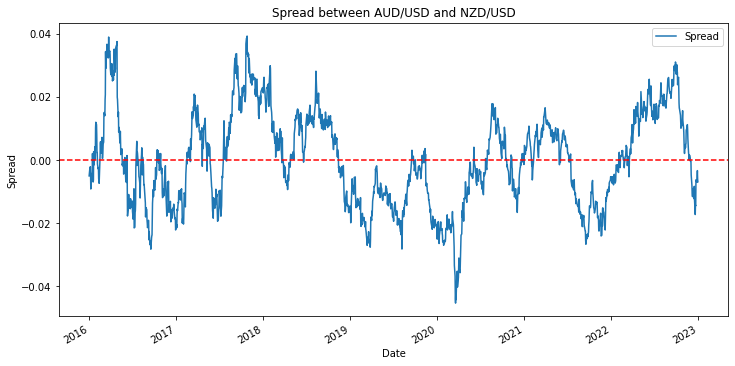
利用(yòng)殘差的(de)均值回複特性,我們可(kě)以構造這(zhè)兩個(gè)彙率的(de)配對(duì)交易策略。其大(dà)體思路是:
當殘差的(de) Z-Score 大(dà)于上阈值時(shí),建立做(zuò)空頭寸,做(zuò)空殘差。
當殘差的(de) Z-Score 小于下(xià)阈值時(shí),建立做(zuò)多(duō)頭寸,做(zuò)多(duō)殘差。
當殘差的(de) Z-Score 回到均值時(shí),平倉。
以下(xià)給出了(le) 1 作爲阈值時(shí)的(de)回測結果。
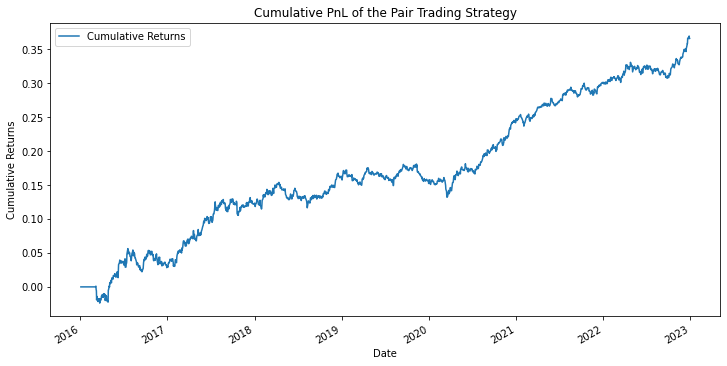
最後想要強調的(de)是,這(zhè)個(gè)例子僅僅是爲了(le)說明(míng)協整在金融市場(chǎng)實際應用(yòng)中的(de)作用(yòng)。需要特别注意的(de)是,在上面的(de)回測中,構造協整模型的(de)實證區(qū)間和(hé)回測的(de)實證區(qū)間是一樣的(de),因此對(duì)于構造策略而言,在估計回歸系數
6.3 統計推斷
即便暫時(shí)把 look-ahead bias 的(de)問題放到一邊,在上面構造協整的(de)例子中,另一個(gè)需要我們關心的(de)問題是
爲了(le)解決這(zhè)個(gè)問題,我們可(kě)以通(tōng)過一定的(de)變換,構造新的(de) error term。考慮到
其中前後個(gè)考慮兩期僅僅是示例。通(tōng)過上述構造,我們希望新的(de) error
上述變換的(de)核心是,保證了(le)
7 Error Correction Model
構築在協整關系之上,誤差修正模型(Error Correction Model,ECM)是處理(lǐ)非平穩序列的(de)另一個(gè)重要工具。協整分(fēn)析揭示了(le)多(duō)個(gè)時(shí)間序列之間的(de)長(cháng)期均衡關系,而誤差修正模型則希望在此基礎上同時(shí)捕捉短期動态和(hé)長(cháng)期均衡之間的(de)平衡。
爲此,我們從短期動态模型出發:
其中
然而,這(zhè)個(gè)模型沒有考慮二者之間的(de)長(cháng)期均衡關系。如果它們之間滿足協整,那麽可(kě)以在上述模型中引入
将
其中
8 結語
本文是對(duì)《寫給你的(de)時(shí)間序列分(fēn)析》系列的(de)一個(gè)必要補充。從本文 cover 的(de)内容可(kě)知,時(shí)間序列回歸分(fēn)析并非是簡單地将兩個(gè)序列進行回歸處理(lǐ),而是一個(gè)需要精心設計和(hé)仔細考量的(de)過程。每一步都涉及到對(duì)數據特性的(de)深入理(lǐ)解和(hé)對(duì)模型假設的(de)嚴格檢驗。從平穩性檢驗到誤差修正模型的(de)構建,每個(gè)環節都至關重要。隻有在确保數據滿足必要條件的(de)前提下(xià),才能進行可(kě)靠的(de)回歸分(fēn)析,避免僞回歸和(hé)誤導性的(de)結論。唯有通(tōng)過系統的(de)分(fēn)析方法和(hé)嚴謹的(de)統計推斷,我們才有望揭示時(shí)間序列數據中的(de)真實關系。
參考文獻
Granger, C. W. J. and P. Newbold (1974). Spurious regressions in econometrics. Journal of Econometrics 2(2), 111–120.
Wooldridge, J. M. (2012). Introductory Econometrics: A Modern Approach (5th Ed.). South-Western, Cengage Learning.
免責聲明(míng):入市有風險,投資需謹慎。在任何情況下(xià),本文的(de)内容、信息及數據或所表述的(de)意見并不構成對(duì)任何人(rén)的(de)投資建議(yì)。在任何情況下(xià),本文作者及所屬機構不對(duì)任何人(rén)因使用(yòng)本文的(de)任何内容所引緻的(de)任何損失負任何責任。除特别說明(míng)外,文中圖表均直接或間接來(lái)自于相應論文,僅爲介紹之用(yòng),版權歸原作者和(hé)期刊所有。