
出色不如走運 (IV)?
發布時(shí)間:2020-04-27 | 來(lái)源: 川總寫量化(huà)
作者:石川
摘要:繼 Harvey, Liu, and Zhu (2016) 把因子顯著性 t-statistic 阈值提升到 3.0 之後,如今它又被提升到 3.4 以上?
00 引言
上周,Review of Financial Studies 發布了(le)最新的(de)一刊(2020 年五月(yuè)刊)。令人(rén)頗爲驚喜的(de)是,它是一個(gè)關于股票(piào)截面收益率研究新方法的(de)特刊(Special Issue: New methods in the cross-section)。下(xià)圖是這(zhè)期的(de)封面,羅列它所包含的(de)文章(zhāng)。除了(le)第一篇是來(lái)自編輯的(de)介紹軟文外,從第二篇 Eugene Fama 和(hé)老搭檔 Ken French 的(de)文章(zhāng)開始就是被收錄的(de)論文。大(dà)咖雲集、衆星閃耀。

關于這(zhè) 9 篇論文,本公衆号和(hé) [因子動物(wù)園] 之前零星介紹過一些(因爲有些能夠在 SSRN 上拿到早期的(de)研究手稿),例如 Fama and French (2020),Daniel et al. (2020) 以及 Gu, Kelly, and Xiu (2020) 等;另外相信各位小夥伴對(duì)于 Hou, Xue, and Zhang (2020) 的(de) Replicating Anomalies 也(yě)一定不陌生(這(zhè)篇文章(zhāng)終于見刊了(le)!)。
本文的(de)目的(de)并非逐一介紹這(zhè)個(gè)特刊收錄每篇論文,而是重點關注其中的(de)一篇。也(yě)許各位已經從本文的(de)題目猜到了(le),它是《出色不如走運》系列的(de)最新一篇,而這(zhè)一系列所闡述的(de)都是到底如何排除運氣的(de)成分(fēn)、找到真正顯著的(de)異象。因此,本文的(de)主要内容就是介紹 Chordia, Goyal, and Saretto (2020) 這(zhè)篇題爲 Anomalies and false rejections 的(de)論文。
當然,由于特刊過于精彩,它精彩的(de)勾勒出關于截面預期收益率研究的(de)三個(gè)趨勢。因此本文也(yě)會對(duì)其進行簡要介紹。下(xià)文的(de)第一節将會深入淺出的(de)解讀 Chordia, Goyal, and Saretto (2020);第二節會介紹特刊中的(de)三大(dà)趨勢;第三節總結。
需要背景知識的(de)小夥伴,請參考本系列的(de)前幾篇文章(zhāng)《出色不如走運?》、《出色不如走運(II)?》以及《出色不如走運(III)?》。
01 Chordia, Goyal, and Saretto (2020)
本節簡要介紹 Chordia, Goyal, and Saretto (2020) 一文的(de)核心思想和(hé)結論。行文會盡可(kě)能采用(yòng)直白的(de)方式,輔以少量的(de)公式。對(duì)技術細節感興趣的(de)小夥伴請直接閱讀論文原文。
近年來(lái),學術界越來(lái)越重視多(duō)重假設檢驗(multiple hypothesis testing,簡稱 MHT 問題)對(duì)異象顯著性的(de)影(yǐng)響。所謂 MHT 問題,就是說當很多(duō)學者對(duì)著(zhe)同樣的(de)數據(過去幾十年的(de)美(měi)股數據)挖異象的(de)時(shí)候,僅靠運氣就能發現很多(duō)顯著的(de)異象。舉個(gè)具象一些的(de)例子,比如同時(shí)測了(le) 100 個(gè)異象,其中最高(gāo)的(de)那個(gè)的(de) t-statistic 就會很高(gāo) —— 哪怕從金融學角度來(lái)說它可(kě)能和(hé)股票(piào)收益率根本沒什(shén)麽關聯。MHT 問題的(de)存在使得(de)單一檢驗的(de) t-statistic 被高(gāo)估了(le),即裏面有運氣的(de)成分(fēn)。當排除了(le)運氣成分(fēn)後,該異象很可(kě)不再顯著。如果仍然按照(zhào)傳統意義上的(de) 2.0 作爲 t-statistic 阈值來(lái)評價異象是否顯著,一定會有很多(duō) false rejections。MHT 問題的(de)核心就是控制 false rejections 發生的(de)概率。這(zhè)意味著(zhe),單一異象的(de) t-statistic 隻有比傳統意義上的(de) 2.0 要高(gāo)的(de)多(duō),那麽這(zhè)個(gè)異象才在控制了(le) false rejections 概率之後仍然有可(kě)能是真實的(de)。
因此,問題的(de)核心就是:t-statistic 的(de)阈值應該是多(duō)少?關于這(zhè)個(gè)問題,統計學和(hé)醫學界做(zuò)過大(dà)量的(de)研究。而金融領域開始(格外)重視它大(dà)概是在近 5 年。其中的(de)代表是 Harvey, Liu, and Zhu (2016) 這(zhè)篇同樣發表在 Review of Financial Studies 上的(de)論文,它把 t-statistic 從 2.0 提升至 3.0。而今天的(de)這(zhè)篇 Chordia, Goyal, and Saretto (2020) 從某種程度上正是對(duì)标了(le) Harvey, Liu, and Zhu (2016)。爲了(le)回答(dá) t-statistic 阈值是多(duō)少,需要有兩個(gè)問題需要解決。先來(lái)看第一個(gè),即使用(yòng)何種算(suàn)法來(lái)控制 false rejections 的(de)概率。就這(zhè)個(gè)問題,學術界提出了(le)很多(duō)不同的(de)方法,下(xià)面借助下(xià)表來(lái)解釋它們。

假設一共研究了(le) S 個(gè)異象,其中 S_0 個(gè)在原假設下(xià)爲真(即不能預測收益率),S_1 個(gè)在原假設下(xià)爲假(即能夠預測收益率)。接下(xià)來(lái),按 5% 的(de)顯著性水(shuǐ)平對(duì)每個(gè) hypothesis 進行檢驗,并一共拒絕了(le) R 個(gè)假設,其中 F_1 個(gè) false rejections(因爲它們的(de)原假設爲真)。使用(yòng) F_1 和(hé) R 可(kě)以定義一些不同的(de)統計量,而不同的(de) MHT 算(suàn)法是以控制不同的(de)統計量爲目标。這(zhè)些統計量包括三大(dà)類:FWER、FDR 和(hé) FDP。
FWER 是 familywise error rate,控制它相當于:
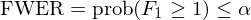
其中 α 爲顯著性水(shuǐ)平。由定義可(kě)知,FWER 是控制出現 1 個(gè) false rejection 的(de)概率。常見的(de)算(suàn)法包括 Bonferroni 和(hé) Holm 方法(見《出色不如走運(II)?》),以及 White (2000) 的(de) bootstrap reality check 算(suàn)法和(hé) Romano and Wolf (2005) 的(de) StepM 算(suàn)法等。毫無疑問,這(zhè)個(gè)控制太過嚴苛,不适用(yòng)于分(fēn)析異象。
FDR 是 false discover rate,它是 F_1/R 的(de)期望。因此控制它相當于:
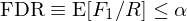
從定義可(kě)知,FDR 比 FWER 要溫和(hé)得(de)多(duō),它允許 F_1 著(zhe) R 的(de)增大(dà)而成比例上升。常見的(de)算(suàn)法爲 BHY 方法(見《出色不如走運(II)?》)。
FDP 是 false discovery proportion,它和(hé) FDR 類似,控制它相當于:
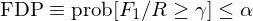
它的(de)含義是控制僞發現比例(F_1/R)超過 γ 的(de)概率低于顯著性水(shuǐ)平 α。這(zhè)其中著名的(de)算(suàn)法包括 Romano and Wolf (2007) 以及 Romano, Shaikh, and Wolf (2008)。
Chordia, Goyal, and Saretto (2020) 選擇的(de)控制 false rejections 的(de)對(duì)象是控制 FDP(他(tā)們并非“憑空想象”而是給出了(le)理(lǐ)由)。該文采用(yòng)了(le) Romano and Wolf (2007) 以及 Romano, Shaikh, and Wolf (2008) 的(de)算(suàn)法,并結合 bootstrap 方法以保留異象之間的(de)相關性。具體方法本文暫且不表,感興趣的(de)朋友請參考論文原文,因爲選擇哪種控制算(suàn)法并不是 Chordia, Goyal, and Saretto (2020) 一文的(de)核心貢獻。
前文說過,要找到正确的(de)阈值,需要解決兩個(gè)問題。第一個(gè)問題是選擇如何控制 false rejections。但是,這(zhè)并不是問題的(de)關鍵。計算(suàn) t-statistic 阈值的(de)關鍵是下(xià)面馬上要介紹的(de)第二個(gè)問題 —— 學術界到底挖了(le)多(duō)少個(gè)異象?爲什(shén)麽說這(zhè)個(gè)問題重要?因爲這(zhè)個(gè)基數決定了(le)運氣的(de)多(duō)寡。這(zhè)就好比,檢驗 100 個(gè)和(hé) 10000 個(gè)異象相比,萬裏挑一的(de)肯定要比百裏挑一的(de)更顯著。所以,隻有知道學術界到底挖了(le)多(duō)少異象,才有可(kě)能正确給出 t-statistic 的(de)阈值,而這(zhè)個(gè)問題比如何控制 false rejections 重要的(de)多(duō)。
有的(de)小夥伴可(kě)能會說 —— 不就那 300 來(lái)個(gè)嗎,就是 Harvey, Liu, and Zhu (2016) 考慮的(de)那些;或者 450 個(gè)左右,就是 Hou, Xue, and Zhang (2020) 複現的(de)那些。答(dá)案并沒有這(zhè)麽簡單。其原因是,一個(gè)異象之所以被發表,顯然因爲它本身達到了(le)傳統意義上的(de)顯著性水(shuǐ)平(如 2.0)。如果一個(gè)學者研究出來(lái)的(de)異象不顯著,那麽他(tā)也(yě)不會針對(duì)它寫篇論文,或者即便寫了(le)也(yě)不會被發表。令 P 代表被發表的(de)異象的(de)集合,R 代表被挖出來(lái)的(de)異象的(de)集合,由上述的(de)論述可(kě)知 P 是 R 的(de)一個(gè)子集。且我們可(kě)以合理(lǐ)的(de)假設它們大(dà)約滿足如下(xià)的(de)關系:
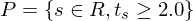
由于 P 僅僅是 R 的(de)子集(“下(xià)界”),使用(yòng) P 來(lái)進行 false rejections 控制隻能低估了(le)運氣的(de)成分(fēn),因此 Harvey, Liu, and Zhu (2016) 找到的(de) 3.0 阈值隻可(kě)能是真實 t-statistic 阈值的(de)下(xià)限。有了(le) R 的(de)“下(xià)界”,再來(lái)看看“上界”。Chordia, Goyal, and Saretto (2020) 使用(yòng)财務三大(dà)表中的(de)指标,經過“無腦(nǎo)”加減乘除運算(suàn),構建了(le) 2,393,641 個(gè)異象。令集合 E 代表這(zhè)些異象,它就是 R 的(de)上界。兩百多(duō)萬個(gè)異象,哇咔咔,但需要說明(míng)的(de)是,這(zhè)些隻是通(tōng)過“無腦(nǎo)”加減乘除得(de)到的(de),這(zhè)可(kě)以理(lǐ)解成從 econometrician(計量經濟學家)的(de)角度找到的(de)異象個(gè)數。
那麽,能不能用(yòng) E 當作異象集來(lái)控制 false rejections 呢(ne)?答(dá)案也(yě)是否定的(de)。Chordia, Goyal, and Saretto (2020) 指出,和(hé) econometrician 們不同,金融學教授那都是有 domain knowledge 的(de),顯然不會胡亂找一個(gè)看著(zhe)就不太可(kě)能預測收益率的(de)變量構建異象。因此,金融學者們研究的(de)異象肯定(遠(yuǎn))小于 2,393,641 個(gè),所以 R 是 E 的(de)子集。綜合上述討(tǎo)論得(de)到:
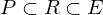
繞了(le)一大(dà)圈似乎啥也(yě)沒解決,還(hái)是不知道 R 有多(duō)大(dà)。别著(zhe)急,确定 R 的(de)統計特征、從而依據其特征控制 false rejections 計算(suàn) t-statistic 阈值就是 Chordia, Goyal, and Saretto (2020) 一文最大(dà)的(de)亮點。而他(tā)們采用(yòng)的(de)方法則是 simulation。Simulation 的(de)好處是 data generating process 是已知的(de),因此能夠知道哪些 H_0 爲真、哪些 H_0 爲假,從而計算(suàn)出正确的(de) t-statistic 阈值。
爲了(le)進行 simulation,就要有模型。該文假設股票(piào)收益率在時(shí)序上滿足如下(xià)多(duō)因子模型:
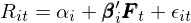
其中 α_i 是模型無法解釋的(de)超額收益。此外,在所有能夠構建異象的(de)變量中,模型假設顯著變量的(de)概率爲 π。對(duì)于該變量,simulation 中假設其在 t 期的(de)取值滿足以下(xià)模型:
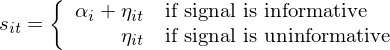
式中 η 滿足正态分(fēn)布 N(0, σ^2),是随機擾動。如果變量是真的(de)異象(發生概率 π),則它對(duì)于股票(piào) i 在 t 期的(de)取值爲 α_i + η_{it}。值得(de)說明(míng)的(de)是,simulation 中當然無從知道異象變量到底應該怎麽取值,但既然真正的(de)異象能夠獲得(de)超額收益,那麽異象變量的(de)取值一定和(hé)個(gè)股的(de) α_i 相關(否則按 portfolio sort 排序就沒法獲得(de)超額收益了(le)),因此令 s_{it} = α_i + η_{it} 是合理(lǐ)的(de)。如果變量是假的(de)異象(發生概率 1 - π),則 s_{it} = η_{it} 是随機噪聲。
除了(le)關于收益率的(de)模型和(hé)異象變量的(de)模型外,simulation 中還(hái)有一個(gè)至關重要的(de)參數 —— Ω。它代表了(le)金融學者們挖出真正異象的(de)能力。怎麽理(lǐ)解呢(ne)?前面已經說了(le) π 是異象的(de)概率,但這(zhè)隻不過是随機抽取的(de)概率。對(duì)于金融學教授來(lái)說,因爲有先驗知識,因此他(tā)們獲得(de)異象的(de)條件概率要高(gāo)于非條件概率 π。這(zhè)個(gè)參數 Ω 就是衡量金融學教授挖出異象的(de)概率,這(zhè)個(gè)概率爲 Ωπ,即二者的(de)乘積。
OK!現在有了(le)模型,隻要知道參數取值就可(kě)以跑仿真了(le)。參數如何取值呢(ne)?對(duì)于收益率模型中的(de)因子收益率、因子暴露以及超額收益,Chordia, Goyal, and Saretto (2020) 采用(yòng)了(le)真實美(měi)股市場(chǎng)數據的(de)分(fēn)布進行估計,而對(duì)于異象變量模型的(de)參數 π、Ω 以及 σ,他(tā)們使用(yòng)了(le)校準。既然要校準,就要給定 target quantities,用(yòng)它們作爲校準參數來(lái)逼近的(de)對(duì)象。爲了(le)解釋這(zhè)些 target quantities,先介紹一個(gè)概念。如果某個(gè) H_0 在單一檢驗下(xià)被拒絕了(le),但是在考慮了(le)多(duō)重假設檢驗後沒有被拒絕,則稱它爲 single, but not multiple(SnM)rejection。
通(tōng)過控制 FDP,Chordia, Goyal, and Saretto (2020) 發現不帶任何先驗的(de)計量經濟學家集合 E 中,SnM 的(de)比例爲 97.9% —— 如此之高(gāo),說明(míng)不帶金融學先驗去挖異象确實不靠譜。回到 simulation,這(zhè)個(gè) SnM 值顯然和(hé)無條件的(de)異象概率 π 有關,因此它就是對(duì) π 校準的(de) target quantity。接下(xià)來(lái)如法炮制,對(duì)于發表的(de)異象集合 P,它的(de) SnM 的(de)比例爲 27.0% —— 看來(lái)金融學教授們要靠譜得(de)多(duō)。這(zhè)個(gè)數值顯然和(hé)異象的(de)條件概率 Ωπ 有關。但是注意這(zhè)個(gè) SnM 是針對(duì)集合 P 的(de),它是被發表的(de)異象,而 Ωπ 所代表的(de)是學者們在研究中挖出顯著異象的(de)概率。因此,使用(yòng) SnM = 27.0% 來(lái)校準 Ωπ 的(de)思路是正确的(de),但是必須帶上 P 和(hé) R 的(de)關系,即 P = {s \in R, t ≥ 2.0}。最後是随機擾動的(de)波動 σ。爲了(le)校準它,Chordia, Goyal, and Saretto (2020) 選擇了(le)兩個(gè) target quantities。爲了(le)便于理(lǐ)解,在此介紹其中一個(gè)。由于 σ 控制随機擾動的(de)波動,因此它直接影(yǐng)響著(zhe)信噪比。該文采用(yòng)下(xià)式來(lái)衡量信噪比:
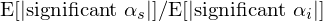
其中分(fēn)子是顯著異象組合超額收益 α_s 絕對(duì)值的(de)期望;分(fēn)母是顯著股票(piào)超額收益 α_i 絕對(duì)值的(de)期望。該比值來(lái)自真實美(měi)股數據,大(dà)小爲 0.12。
有了(le)上述這(zhè)些,Chordia, Goyal, and Saretto (2020) 通(tōng)過全局優化(huà)算(suàn)法求解,并平均了(le) 1000 次 simulation 結果确定了(le) π、Ω 以及 σ 的(de)取值。再次強調的(de)是,有了(le)這(zhè)些取值,就相當于整個(gè)學者挖異象的(de) data generating process 是已知的(de)了(le)!利用(yòng)這(zhè)些參數,和(hé)前述的(de)股票(piào)收益率和(hé)異象變量模型,他(tā)們又進行了(le) 1000 次 simulation —— 這(zhè)次是爲了(le)模拟 R 集合下(xià)(學者們挖掘異象的(de)集合),當控制了(le) FDP 之後 t-statistic 應該是多(duō)少。最後,Chordia, Goyal, and Saretto (2020) 發現,如果以 portfolio sort 的(de)超額收益(時(shí)序回歸,用(yòng)多(duō)因子模型作爲解釋變量)爲研究對(duì)象,其 t-statistic 阈值高(gāo)達 3.8;如果以 Fama-MacBeth 回歸斜率(即在控制了(le)其他(tā)變量後異象的(de)收益率)爲研究對(duì)象,其 t-statistic 阈值高(gāo)達 3.4。一般來(lái)說,比起 portfolio sort,Fama-MacBeth 回歸更不容易受多(duō)重假設檢驗影(yǐng)響,因此其 t-statistic 阈值略低。但無論如何,這(zhè)兩個(gè)數值均高(gāo)于 Harvey, Liu, and Zhu (2016) 提出的(de) 3.0,符合預期。以上這(zhè)兩個(gè)阈值就是 Chordia, Goyal, and Saretto (2020) 一文的(de)核心結論。除此之外,該文還(hái)通(tōng)過 simulation 計算(suàn)了(le) false rejections 比例(即 F_1/R),高(gāo)達 45.3%。
呼!我希望你沒有 get lost!
02 截面研究新趨勢
本節簡要介紹本期 RFS 特刊中關于截面收益率研究的(de)三個(gè)趨勢(下(xià)圖)。

本期一共收錄 9 篇文章(zhāng),每個(gè)趨勢下(xià)三篇。第一個(gè)趨勢是 extracting information from both the cross-section and time series。其實,用(yòng)白話(huà)說,它的(de)意思就是 portfolio sort vs cross-sectional regression。
從 Fama-French 三因子模型開始,用(yòng) portfolio sort 構建因子投資組合,計算(suàn)其收益率作爲因子便是多(duō)因子模型中采用(yòng)的(de)做(zuò)法,無一例外。然而,越來(lái)越多(duō)的(de)研究,包括 Fama 自己都發現,截面回歸的(de)純因子組合似乎更能解釋截面預期收益率的(de)差異。因此,從這(zhè)兩個(gè)角度去理(lǐ)解因子就是第一個(gè)趨勢。這(zhè)個(gè)話(huà)題下(xià)的(de)三篇文章(zhāng)是:

對(duì)于上面第一篇,《Which Beta (II)?》一文做(zuò)過詳細解讀;而第二篇,[因子動物(wù)園] 的(de)《對(duì)沖:獲取更純粹的(de) CP》一文進行了(le)系統說明(míng)。第三篇嘛,還(hái)沒看……不過排上号了(le)。
第二個(gè)趨勢是 replicating anomalies, multiple hypothesis testing, and transaction costs,包括如下(xià)三篇:

其中 Replicating anomalies 不用(yòng)做(zuò)太多(duō)介紹了(le),而本文重點梳理(lǐ)了(le)其中第二篇。至于第三篇嘛,again,還(hái)沒看……不過也(yě)排上号了(le)。
最後一個(gè)趨勢是 machine-learning tools,它關注如何将機器學習(xí)算(suàn)法科學的(de)應用(yòng)在古老的(de)實質資産定價之中。這(zhè)個(gè)話(huà)題下(xià)包含的(de)三篇文章(zhāng)爲:

其中第一篇 Gu, Kelly, and Xiu (2020) 是最近一兩年非常火的(de)一篇論文。[因子動物(wù)園] 的(de)《因子投資中的(de)機器學習(xí)》一文對(duì)它進行了(le)梳理(lǐ)。第二篇提出了(le)一個(gè) PCA estimator,在降維的(de)同時(shí)保留主成分(fēn)對(duì)截面收益率的(de)預測能力。第三篇則提出了(le)一個(gè)非參數的(de)方法,從 62 個(gè)常見的(de)收益率預測變量中找到 13 個(gè)真正有效的(de)。今後會找機會介紹這(zhè)些新的(de)方法。
03 結語
本期 RFS 特刊在描述三大(dà)趨勢的(de)同時(shí)也(yě)給出了(le)四個(gè)展望,不妨以它們作爲本文的(de)結尾:
1. 重視 multiple hypothesis testing 問題,形成科研中更好的(de)研究流程,避免 publication bias,data snooping 以及 p-hacking。
2. 不同降維方法極大(dà)減少了(le)因子的(de)個(gè)數(通(tōng)常不超過 10 個(gè))。不過有意思的(de)是,不同方法得(de)到的(de)因子可(kě)能差異很大(dà),在這(zhè)方面學術界需要尋求 common ground across methods。
3. 根據資産定價理(lǐ)論,SDF(随機折現因子)其實是 factors 的(de)某種線性組合。因此隻有 factors 有意義,SDF 才有意義。從這(zhè)個(gè)意義上說,無論采用(yòng)傳統方法還(hái)是新的(de)機器學習(xí)算(suàn)法,都要重視因子的(de)經濟學含義。
4. 将源于預測股票(piào)收益率的(de)這(zhè)些新方法應用(yòng)于金融學的(de)其他(tā)領域,比如預測其他(tā)資産,或者用(yòng)于評價基金經理(lǐ)以及公司決策等領域。
毫無疑問,這(zhè)期 RFS 特刊十分(fēn)過瘾。而我們也(yě)有理(lǐ)由相信,未來(lái)關于實證資産定價和(hé)因子投資的(de)研究會更加精彩。
感謝閱讀,預祝各位五一快(kuài)樂(yuè)。
參考文獻
Chordia, T., A. Goyal, and A. Saretto (2020). Anomalies and false rejections. Review of Financial Studies 33(5), 2134 – 2179.
Daniel, K., L. Mota, S. Rottke, and T. Santos (2020). The cross-section of risk and returns. Review of Financial Studies 33(5), 1927 – 1979.
Fama, E. F. and K. R. French (2020). Comparing cross-section and time-series factor models. Review of Financial Studies 33(5), 1891 – 1926.
Gu, S., B. Kelly, and D. Xiu (2020). Empirical asset pricing via machine learning. Review of Financial Studies 33(5), 2223 – 2273.
Harvey, C. R., Y. Liu, and H. Zhu (2016). … and the cross-section of expected returns. Review of Financial Studies 29(1), 5 – 68.
Hou, K., C. Xue, and L. Zhang (2020). Replicating anomalies. Review of Financial Studies 33(5), 2019 – 2133.
Romano, J. P., A. M. Shaikh, and M. Wolf (2008). Formalized data snooping based on generalized error rates. Econometric Theory 24(2), 404 – 447.
Romano, J. P. and M. Wolf (2005). Stepwise multiple testing as formalized data snooping. Econometrica 73(4), 1237 – 1282.
Romano, J. P. and M. Wolf (2007). Control of generalized error rates in multiple testing. The Annals of Statistics 35(4), 1378 – 1408.
White, H. (2000). A reality check for data snooping. Econometrica 68(5), 1097 – 1126.
免責聲明(míng):入市有風險,投資需謹慎。在任何情況下(xià),本文的(de)内容、信息及數據或所表述的(de)意見并不構成對(duì)任何人(rén)的(de)投資建議(yì)。在任何情況下(xià),本文作者及所屬機構不對(duì)任何人(rén)因使用(yòng)本文的(de)任何内容所引緻的(de)任何損失負任何責任。除特别說明(míng)外,文中圖表均直接或間接來(lái)自于相應論文,僅爲介紹之用(yòng),版權歸原作者和(hé)期刊所有。