
在追逐 p-value 的(de)道路上狂奔,卻在科學的(de)道路上漸行漸遠(yuǎn)
發布時(shí)間:2017-08-16 | 來(lái)源: 川總寫量化(huà)
作者:石川
我最近讀了(le)美(měi)國金融協會(AFA,American Finance Association)前主席 Campbell Harvey 于 2017 年協會年會上做(zuò)的(de)題爲《The Scientific Outlook in Financial Economics》的(de)主席報告,感觸頗深,醍醐灌頂。以一個(gè)學者應有的(de)科學态度和(hé)操守,Dr. Harvey 深刻剖析了(le)近年來(lái)西方學術界在收益率風險多(duō)因子模型研究中的(de)一個(gè)錯誤趨勢:
爲了(le)競逐在頂級期刊上發表文章(zhāng),學者們過度追求因子在原假設下(xià)的(de)低 p-value 值(即統計意義上“顯著”);不幸的(de)是,由于有意或無意的(de)數據操縱、使用(yòng)不嚴謹的(de)統計檢驗手段、錯誤地解釋 p-value 傳達的(de)意義、以及忽視因子本身的(de)業務含義,很多(duō)在功利心驅使下(xià)被創造出來(lái)的(de)收益率因子在實際投資中根本站不住腳。
學者們在追逐 p-value 的(de)道路上狂奔,卻在科學的(de)道路上漸行漸遠(yuǎn)。
我看完之後産生了(le)深深的(de)共鳴:難怪我在頂級期刊上以及賣方的(de)研究報告中看到的(de)很多(duō)因子,僅僅是在報告中“看起來(lái)有效”。在這(zhè)個(gè)急功近利的(de)時(shí)代,Dr. Harvey 大(dà)聲呼籲學術界應該後退一步(take a step back),重新審視一下(xià)學術氛圍和(hé)文化(huà),真正做(zuò)到以推動人(rén)們對(duì)金融經濟學的(de)正确認知爲己任。這(zhè)無疑是量化(huà)投資領域的(de)福音(yīn)。此外,Dr. Harvey 還(hái)提出了(le)貝葉斯 p-value 的(de)概念,它可(kě)以正确地評價因子的(de)有效性。
1 p-value
先來(lái)看看什(shén)麽是 p-value,以及它在因子分(fēn)析中的(de)作用(yòng)。(本節内容是我加的(de)。)假設我們有一個(gè)因子 A,在學術界研究該因子能否獲得(de)超額收益時(shí),一般的(de)流程如下(xià):
1. 首先提出原假設(null hypothesis):使用(yòng)因子(異象) A 無法獲得(de)超額收益。
2. 使用(yòng)因子 A 選股、配置多(duō)空投資組合,然後用(yòng)某主流的(de)多(duō)因子定價模型來(lái)檢驗該因子是否能夠獲得(de)定價模型無法解釋的(de)超額收益。
3. 比較因子 A 超額收益的(de) p-value 是否小于給定的(de)顯著性水(shuǐ)平,從而決定是否拒絕原假設。拒絕原假設意味著(zhe)拒絕“因子 A 能夠獲得(de)超額收益”。
可(kě)見,p-value 在上述過程中至關重要。p-value 是 probability value 的(de)簡稱。在統計檢驗中,假設統計模型對(duì)應的(de)原假設是 H,該模型觀測到的(de)随機變量 X 的(de)取值爲 x,則 p-value 代表著(zhe)在原假設 H 下(xià)随機變量 X 取到比 x 更加極端的(de)數值的(de)條件概率,即:
對(duì)于右尾極端事件:p-value = prob(X ≥ x|H);
對(duì)于左尾極端事件:p-value = prob(X ≤ x|H);
對(duì)于雙尾極端事件:p-value = 2 × min{ prob(X ≥ x|H), prob(X ≤ x|H)}。
The null hypothesis is usually a statement of no relation between variables or no effect of an experimental manipulation. The p-value is the probability of observing an outcome or a more extreme outcome if the null hypothesis is true (Fisher 1925).
對(duì)于股票(piào)收益率因子模型領域,因爲我們希望找到可(kě)以帶來(lái)超額正收益的(de)因子,所以 p-value 一般指的(de)是上面第一種定義,即 p-value = prob(X ≥ x|H)。例如,當 p-value = 0.05 時(shí),我們說在原假設 H 下(xià)觀測到不小于 x 的(de)超額收益的(de)條件概率爲 5%;當 p-value = 0.01 時(shí),我們說在原假設 H 下(xià)觀測到不小于 x 的(de)超額收益的(de)條件概率僅有 1%。顯然,p-value 越小說明(míng)在原假設 H 下(xià)觀測到不小于 x 的(de)超額收益的(de)可(kě)能性越低,即發生“不小于 x 超額收益”這(zhè)個(gè)事件和(hé)原假設 H 越不相符,我們越傾向于拒絕原假設。
當“因子 A 無法獲得(de)超額收益”這(zhè)個(gè)原假設被拒絕時(shí),人(rén)們便會推論出“因子 A 能夠獲得(de)超額收益”。如此,人(rén)們習(xí)慣把“p-value 越低”和(hé)“因子 A 越能獲得(de)超額收益”等價起來(lái)了(le)。這(zhè)就是爲什(shén)麽我們都喜歡低的(de) p-value。但它們真的(de)等價嗎?低的(de) p-value 僅僅是某個(gè)因子能獲得(de)超額收益的(de)必要條件;但是它遠(yuǎn)不是充分(fēn)條件。有意或者無意的(de)數據操縱(data manipulation)以及不完善的(de)統計檢驗所得(de)到的(de)低的(de) p-value 在說明(míng)因子是否有效方面毫無作用(yòng)。
2 p-hacking
好了(le),現在我們已經知道了(le) p-value 在因子模型中的(de)作用(yòng):要想說明(míng)某個(gè)因子有效,最起碼得(de)有個(gè)低的(de) p-value;否則免談。在這(zhè)種暗示下(xià),學術界便自上而下(xià)的(de)刮起了(le)一股追求超低 p-value 之風。以下(xià)就是因子模型 p-value 在學術界的(de)因果關系鏈:
“p-value 越低意味著(zhe)因子越顯著。" -> “因子越顯著,研究成果越吸引眼球。” -> “成果越吸引眼球越有可(kě)能得(de)到更高(gāo)的(de)引用(yòng)。” -> “高(gāo)引用(yòng)的(de)文章(zhāng)越多(duō),期刊的(de)影(yǐng)響因子越高(gāo)。” -> “期刊的(de)影(yǐng)響因子越高(gāo),期刊的(de)學術聲望越高(gāo)。”
爲了(le)提升期刊的(de)聲望,編輯們都更傾向于錄用(yòng)低 p-value 因子的(de)文章(zhāng);爲了(le)在更高(gāo)水(shuǐ)平的(de)期刊上發文,學者們更傾向于找到低 p-value 的(de)因子。在美(měi)國絕大(dà)多(duō)數學校裏,如果能在 Journal of Finance 發表一篇文章(zhāng),一個(gè)教授就有可(kě)能得(de)到終身教職(tenure)。在如今的(de)金融經濟學領域,這(zhè)樣的(de)做(zuò)法無奈的(de)導緻了(le)一種發表偏差(publication bias):學者們更願意把時(shí)間和(hé)精力花到可(kě)以利用(yòng)各種手段來(lái)找到低 p-value 的(de)因子上,隻願意發表“看上去最顯著”的(de)研究成果。他(tā)們不願意冒險來(lái)研究“無效的(de)因子”。
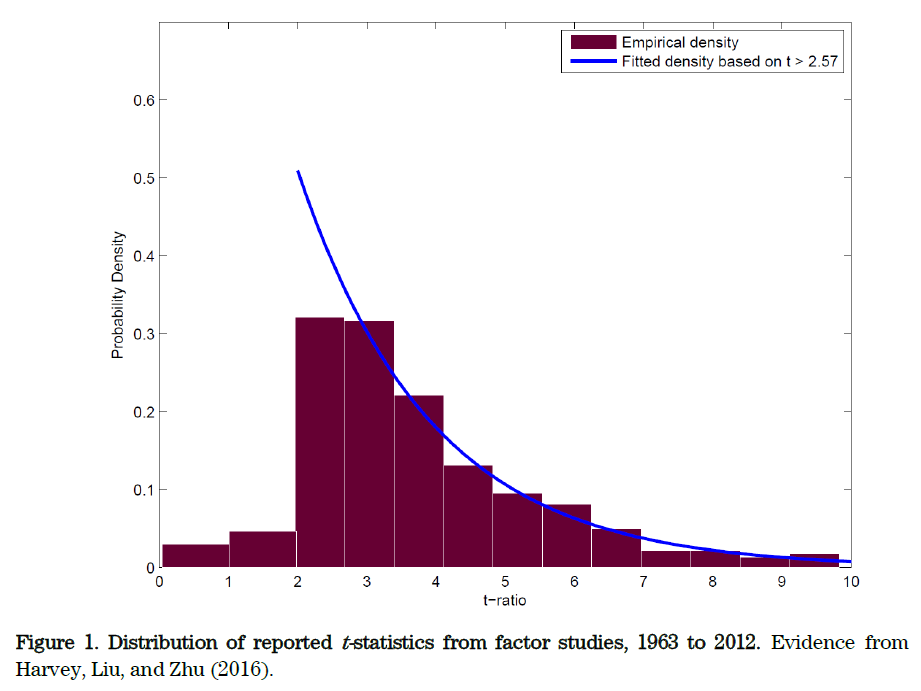
從推動學科發展的(de)角度,“無效的(de)因子”和(hé)“有效的(de)因子”同樣重要。如果我們能夠确切的(de)證明(míng)某個(gè)因子就是無法帶來(lái)超額收益,那麽它對(duì)實際中選股也(yě)是非常有價值的(de)(我們可(kě)以放心的(de)避開該因子)。然而,在追求超低 p-value 之風下(xià),學者不願意進行這(zhè)樣的(de)研究,因爲頂級期刊上鮮有它們的(de)容身之處。下(xià)圖出自 Harvey, Liu, and Zhu (2016)。他(tā)們分(fēn)析了(le) 1963 年到 2012 年間發表在金融領域最頂級期刊上的(de) 300 多(duō)個(gè)因子模型的(de) t-statistics(可(kě)以簡單的(de)理(lǐ)解爲 p-value 越低,其對(duì)應的(de) t-statistics 越高(gāo))的(de)分(fēn)布情況。這(zhè)個(gè)分(fēn)布清晰地說明(míng)了(le)學術界的(de)發表偏差。比如,t-statistics 取值在 2 到 2.57 的(de)文章(zhāng)數和(hé) t-statistics 取值在 2.57 到 3.14 的(de)文章(zhāng)數十分(fēn)接近。要知道,t-statistics = 2.57 對(duì)應的(de) p-value 大(dà)概是 0.005;而 t-statistics = 3 對(duì)應的(de) p-value 則是 0.001!顯然,找到 p-value = 0.001 的(de)因子要比找到 p-value = 0.005 的(de)因子要困難得(de)多(duō),但它們的(de)文章(zhāng)數量卻大(dà)緻相當。這(zhè)隻能說明(míng)在頂級期刊發表文章(zhāng)時(shí),學者們傾向于更低的(de) p-value。
3 硬科學與軟科學
看到這(zhè)裏,人(rén)們不禁要問怎麽會有這(zhè)麽多(duō)低 p-value 的(de)因子?這(zhè)可(kě)以從“硬科學”和(hé)“軟科學”的(de)角度來(lái)解釋。法國著名的(de)哲學家奧古斯特 • 孔德将科學分(fēn)成不同的(de)等級(Comte 1856)。像數學、物(wù)理(lǐ)這(zhè)類的(de)“硬科學”位于等級的(de)上方,而社會學(包括今天所說的(de)經濟學或者哲學)這(zhè)類“軟科學”位于等級的(de)下(xià)方。這(zhè)裏“硬”和(hé)“軟”并沒有“好”與“壞”之分(fēn)。
在“硬科學”中,人(rén)的(de)痕迹幾乎可(kě)以不存在,從數據可(kě)以直接得(de)到結論、無需任何人(rén)工解釋,且結論是高(gāo)度可(kě)歸納的(de)。比如數學上的(de)四色問題,一旦證明(míng)成立那就是成立;又如物(wù)理(lǐ)上的(de)引力波,一旦發現那就是說明(míng)它的(de)存在,這(zhè)些都是确切的(de)。反觀“軟科學”中,人(rén)的(de)痕迹便會更加明(míng)顯,研究成果依賴于提出怎樣的(de)假設,如何處理(lǐ)數據,以及如何分(fēn)析、解釋結果。這(zhè)些都和(hé)研究者自身的(de)聲望、利益、個(gè)人(rén)偏好有關,因此結果往往是無法歸納的(de)。金融學中的(de)多(duō)因子模型無疑是軟科學,因子選取、原假設的(de)構建、以及數據分(fēn)析都會因人(rén)而異。
比如“使用(yòng)過去 50 年的(de)數據還(hái)是過去 30 年的(de)數據?”“使用(yòng)美(měi)股還(hái)是其他(tā)國家的(de)股票(piào)?”“使用(yòng)日收益率還(hái)是周收益率?”“使用(yòng)百分(fēn)比收益率還(hái)是對(duì)數收益率?”“是否以及如何剔除異常值?”“使用(yòng)線性回歸還(hái)是邏輯回歸?”“使用(yòng)截面回歸還(hái)是時(shí)間序列回歸?”“因子對(duì) 500 個(gè)公司有效但是對(duì) 1000 個(gè)公司無效,因此發文時(shí)僅提及那 500 個(gè)公司。”……在追逐超低 p-value 的(de)背景下(xià),學者在面臨這(zhè)些選擇做(zuò)決定時(shí)會“非常微妙”,一切阻礙超低 p-value 誕生的(de)數據都會被巧妙的(de)避開。Harvey 教授将爲了(le)追求超低 p-value 而在因子研究中刻意選取的(de)數據處理(lǐ)方法稱爲 p-hacking。
在科學研究中,我們往往先觀察事物(wù)是如何運作的(de),然後提出一個(gè)假設并通(tōng)過數據來(lái)驗證其是否成立,可(kě)謂“先有假設再有結果”。然而,p-hacking 卻可(kě)能使我們本末倒置,“先有結果再有假設!”(Hypothesizing after the results are known,稱爲 HARKing)。比如我們的(de)假設是變量 Y 和(hé) X1 相關。爲此我們設計了(le)一個(gè)實驗,并控制了(le) X2 到 X10 其他(tā) 9 個(gè)變量,來(lái)考察 Y 和(hé) X1 的(de)關系。但是實驗結果表明(míng) Y 卻和(hé) X7 相關。因此,我們就會輕易地(不負責任地)把假設改爲“Y 和(hé) X7 相關”,而忘記了(le)研究的(de)初衷。由于數據分(fēn)析的(de)成本很低,HARKing 在因子模型研究中非常普遍。所有這(zhè)一切對(duì)超低 p-value 的(de)追逐都源于人(rén)們的(de)一個(gè)誤解:“p-value 越低”等價于“因子 A 在解釋超額收益上越有效”。下(xià)面來(lái)看看 p-value 到底意味著(zhe)什(shén)麽。
4 正确認識 p-value
人(rén)們對(duì) p-value 的(de)正确含義充滿了(le)誤解。爲了(le)說明(míng)這(zhè)一點,Dr. Harvey 給出了(le)一個(gè)假想的(de)例子。假設一個(gè)選股因子爲董事會的(de)規模。由此我們把上市公司分(fēn)爲兩類:小型董事會的(de)公司和(hé)大(dà)型董事會的(de)公司。原假設 H 是:董事會規模與超額收益無關。比較這(zhè)兩類股票(piào)的(de)收益率均值,我們得(de)到該因子的(de) p-value 小于 0.01。那麽,下(xià)面 4 種關于 p-value 的(de)陳述哪些是正确的(de)呢(ne)(原文中是 6 個(gè)陳述,爲了(le)簡化(huà)討(tǎo)論這(zhè)裏隻包含其中 4 個(gè))?
1. 我們證明(míng)了(le)原假設是錯誤的(de)。
2. 我們找到了(le)原假設爲真的(de)概率,即 prob(H|D)。
3. 我們證明(míng)了(le)小型董事會的(de)公司比大(dà)型董事會的(de)公司有更高(gāo)的(de)超額收益。
4. 我們可(kě)以推斷出“小型董事會的(de)公司比大(dà)型董事會的(de)公司有更高(gāo)的(de)超額收益”爲真的(de)概率,即 prob(H^c|D)。
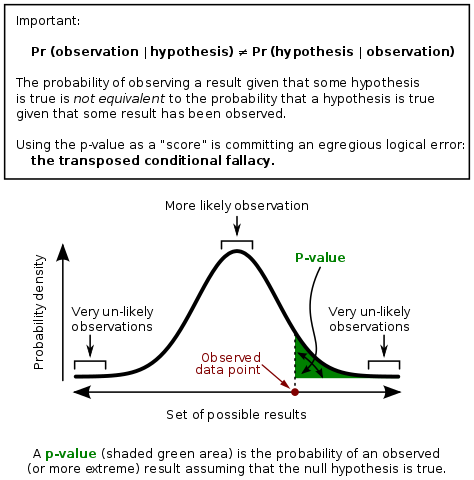
怎麽樣?你覺著(zhe)上面四個(gè)陳述中有幾個(gè)是正确的(de)?答(dá)案是:它們都是錯的(de)。p-value 代表著(zhe)原假設下(xià)觀測到某(極端)事件的(de)條件概率。以 D 代表極端事件,則 p-value = prob(D|H)。從它的(de)定義出發,p-value 不代表原假設或者備擇假設是否爲真實的(de)。因此,上述中的(de) 1 和(hé) 3 都是錯的(de)。
P-value is a statement about data in relation to a specified hypothetical explanation, and is not a statement about the explanation itself.
再強調一遍:p-value 是原假設 H 成立下(xià),D 發生的(de)條件概率,即 prob(D|H);它不是 prob(H|D),即 D 發生時(shí) H 爲真的(de)條件概率。因此 2 也(yě)是錯的(de)。同理(lǐ),p-value 也(yě)和(hé) p(H^c|D)——H^c 代表備擇假設——沒有任何關系,因此 4 也(yě)是錯的(de)。
prob(D|H) ≠ prob(H|D)
prob(D|H) ≠ prob(H|D)
prob(D|H) ≠ prob(H|D)
在這(zhè)個(gè)例子中,最重要的(de)信息就是 p-value 等于 prob(D|H);而人(rén)們往往把它和(hé) prob(H|D) 混淆,這(zhè)是因爲我們太想知道 prob(H|D) 了(le),因爲它告訴我們原假設 H 在 D 發生時(shí)爲真的(de)條件概率。然而 p-value 不等于它。把 prob(D|H) 當成 prob(H|D) 是一個(gè)非常嚴重的(de)錯誤。來(lái)看一個(gè)形象的(de)例子(出自 Carver 1978):
定義兩個(gè)事件:人(rén)死了(le),記爲 D;人(rén)上吊,記爲 H。那麽,prob(D|H) 表示人(rén)因爲上吊而死的(de)概率。這(zhè)個(gè)概率可(kě)能是很高(gāo)的(de),比如 0.97。讓我們把 D 和(hé) H 的(de)位置調換一下(xià),即 prob(H|D),則問題變成了(le)在人(rén)死了(le)的(de)前提下(xià),他(tā)是因爲上吊而死的(de)條件概率。怎麽樣?在這(zhè)個(gè)問題中,因爲我們知道人(rén)的(de)死法有很多(duō)種,比如上吊、跳樓、服毒、割腕……我們不會将 prob(D|H) 的(de)取值等價于 prob(H|D) 而脫口而出 0.97。在這(zhè)個(gè)問題中,prob(D|H) ≠ prob(H|D) 顯而易見。然而當我們解釋因子分(fēn)析的(de) p-value 時(shí),卻總繞不過彎,總将它倆混爲一談。
最後,來(lái)看美(měi)國統計協會(American Statistical Association)關于 p-value 的(de) 6 個(gè)準則(Wasserstein and Lazar 2016):
1. P-values can indicate how incompatible the data are with a specified statistical model.
譯:P-value 可(kě)以表示數據和(hé)給定統計模型的(de)不兼容程度。
2. P-values do not measure the probability that the studied hypothesis is true, or the probability that the data were produced by random chance alone.
譯:P-value 不表示所研究的(de)假設爲真的(de)概率;同時(shí),它也(yě)不表示數據僅由随機因素産生的(de)概率。
3. Scientific conclusions and business or policy decisions should not be based only on whether a p-value passes a specific threshold.
譯:科學結論和(hé)商業或政策決策不應隻根據 P-value 是否通(tōng)過給定的(de)阈值而确定。
4. Proper inference requires full reporting and transparency.
譯:全面的(de)分(fēn)析報告和(hé)完全的(de)透明(míng)度是适當的(de)統計推斷的(de)必要前提。(這(zhè)說的(de)就是要摒除 p-hacking 的(de)問題。)
5. A p-value, or statistical significance, does not measure the size of an effect or the importance of a result.
譯:P-value 或統計上的(de)重要性并不能衡量效用(yòng)的(de)大(dà)小或結果的(de)重要性。(這(zhè)是我們通(tōng)常說的(de)統計上顯著未必具有重要的(de)經濟意義——economic significance)
6. By itself, a p-value does not provide a good measure of evidence regarding a model or hypothesis.
譯:關于模型或者假設是否有效,p-value 本身并不提供足夠的(de)證據。
相信上面這(zhè) 6 點一定會幫助我們更好的(de)理(lǐ)解 p-value 的(de)意義。
5 失真的(de) p-value
如前所述,p-value 用(yòng)來(lái)說明(míng)某種效用(yòng)(effect)是否在統計上顯著(因子可(kě)以解釋股票(piào)的(de)超額收益率就可(kě)以理(lǐ)解爲一種效用(yòng))。當待檢驗的(de)效用(yòng)非常罕見時(shí),統計檢驗得(de)到的(de) p-value 往往是失真的(de)。在醫學中,這(zhè)樣的(de)例子屢見不鮮。假設我們要測試一種罕見的(de)疾病(疾病就是效用(yòng),罕見說明(míng)它本身出現的(de)概率非常低)。原假設就是病人(rén)沒有得(de)病。假設這(zhè)種疾病的(de)發病率爲 1%。我們使用(yòng)某種測試手段對(duì) 1000 名志願者進行篩查。該測試手段的(de)正确率爲 90%(即對(duì)于确實患病的(de)患者,該測試結果爲陽性的(de)概率爲 90%);此外,該測試手段的(de)誤診率爲 10%(即,對(duì)于沒有得(de)病的(de)志願者,它誤診爲陽性的(de)概率爲 10%)。根據 1% 的(de)發病率和(hé) 1000 名志願者,我們假設他(tā)們中間有 10 名真正患者和(hé) 990 名正常。對(duì)于這(zhè) 10 名患者,該檢測手段成功的(de)找到 9 名患者;而對(duì)于剩下(xià) 990 名非患者,它誤診了(le) 99 名。因此,一共有 108 名志願者被診斷爲患病,但其中僅有 9 名是真正的(de)患者。換句話(huà)說,這(zhè)個(gè)測試的(de) false discovery rate 高(gāo)達 92% (= 99 / 108),遠(yuǎn)高(gāo)于該測試手段 10% 的(de)誤診率。在統計檢驗中,false discovery rate 是僞發現率,其意義爲錯誤拒絕(拒絕真的(de)原假設)的(de)個(gè)數占所有被拒絕的(de)原假設個(gè)數的(de)比例的(de)期望值。
上述討(tǎo)論對(duì)金融經濟學有什(shén)麽啓示?這(zhè)裏的(de)核心是,如果一個(gè)效用(yòng)本身越不可(kě)能發生,我們越要小心,因爲會有大(dà)量的(de) false discoveries。令 π 代表在現實中我們找到一個(gè)真實因果關系的(de)概率(即一個(gè)真實的(de)因子),α 代表原假設爲真時(shí)的(de)顯著性水(shuǐ)平,β 表示備擇假設爲真時(shí)檢驗正确的(de)拒絕原假設的(de)概率。從上面這(zhè)個(gè)例子中可(kě)以歸納出,由于效用(yòng)的(de)罕見性,我們能夠預期的(de) false discovery rate 等于:
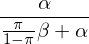
當 β = 1 時(shí),上述 false discovery rate 有理(lǐ)論的(de)最小值。當找到真實因子的(de)概率很低時(shí),π 相對(duì)于 α 很低,該 false discovery rate 近似爲 1。因此,如果發現有效因子本身這(zhè)件事是一個(gè)極小概率事件,則無論我們得(de)到了(le)多(duō)低的(de) p-value,我們的(de)僞發現率(false discovery rate)也(yě)是非常高(gāo)的(de)。不幸的(de)是,發現真實有效的(de)因子本身就是一個(gè)極小概率事件。因此,大(dà)量發表于頂級期刊上的(de)收益率因子都會在将來(lái)被證僞。Bartsch et. al. (2017) 就提供了(le)這(zhè)樣的(de)證據。他(tā)們采用(yòng)了(le)一個(gè)多(duō)重檢驗框架,檢驗了(le)學術界的(de) 100 個(gè)收益率預測模型,得(de)到的(de)結論是模型中的(de)預測能力全部來(lái)自數據遷就(data snooping,即 p-hacking),這(zhè)些模型在新測試框架下(xià)的(de)預測準确性均無法戰勝曆史均值。
6 先驗的(de)重要性,做(zuò)貝葉斯的(de)信徒
上一節的(de)論述傳遞出一個(gè)重要的(de)觀點:我們需要對(duì)效用(yòng)本身發生的(de)概率(例如找到真實收益率因子的(de)概率)有一個(gè)正确的(de)先驗判斷,并用(yòng)它和(hé) p-value 一起計算(suàn)出一個(gè)後驗概率,并以此判斷是否應該拒絕原假設。在生活中,先驗概率對(duì)于我們判斷一個(gè)效用(yòng)是否真的(de)有效至關重要。來(lái)看下(xià)面三個(gè)例子。
第一個(gè)例子:有一個(gè)音(yīn)樂(yuè)家聲稱可(kě)以完美(měi)的(de)區(qū)分(fēn)莫紮特和(hé)海頓的(de)樂(yuè)譜。我們将 10 張樂(yuè)譜給他(tā)辨識,他(tā)全部正确。
第二個(gè)例子:有一個(gè)常年喝茶的(de)老婦人(rén),她聲稱可(kě)以說出一杯加了(le)奶的(de)熱(rè)茶中,奶是先于茶還(hái)是後于茶加入杯中的(de)。同樣,我們将 10 杯請她辨識,她全部正确。
第三個(gè)例子:有一個(gè)酒館老闆,号稱酒精賜予他(tā)預測未來(lái)的(de)神力。我們讓他(tā)猜扔硬币的(de)正反面,結果他(tā)也(yě)是 10 次全對(duì)。
在這(zhè)三個(gè)實驗中,p-value 都遠(yuǎn)低于 0.001( 2 的(de) -10 次方)。然而同樣的(de) p-value 在這(zhè)三個(gè)例子中帶給我們的(de)認知卻截然不同。在第一個(gè)例子中,我們知道對(duì)方是一個(gè)音(yīn)樂(yuè)家,他(tā)分(fēn)辨樂(yuè)譜應該易如反掌。我們的(de)先驗信仰就是他(tā)能夠成功,實驗的(de)結果隻不過确認了(le)這(zhè)一點。在第二個(gè)例子中,我們也(yě)許心存懷疑(先驗),不相信老婦人(rén)能夠成功(原假設是她沒有分(fēn)辨奶加入茶杯順序的(de)能力),然而 10 次全對(duì)(超低 p-value)的(de)結果讓我們傾向于推翻自己的(de)先驗認知,即拒絕原假設,并認爲她确實有這(zhè)個(gè)能力。在第三個(gè)例子中,我們會認爲這(zhè)個(gè)人(rén)就是騙子(酒精能夠預測未來(lái)?),因此打從心底完全不屑(原假設是酒精不能預測未來(lái)),在這(zhè)種情況下(xià),即便他(tā)猜對(duì)了(le) 10 次,我們也(yě)不會推翻原假設(因爲“酒精能夠預測未來(lái)”這(zhè)件事的(de)先驗概率太低了(le)),而僅僅認爲他(tā)是運氣好罷了(le)。
怎麽樣,從這(zhè)三個(gè)例子中看出先驗在解讀 p-value 時(shí)起到的(de)作用(yòng)了(le)嗎?這(zhè)就是貝葉斯框架的(de)強大(dà)之處。Harvey 教授将傳統的(de) p-value 嵌入到貝葉斯框架中,提出了(le)貝葉斯化(huà) p-value(Bayesianized p-value)的(de)概念,它是一個(gè)後驗概率。貝葉斯化(huà) p-value 由最小貝葉斯因子(minimum Bayes factor,MBF)和(hé)先驗幾率(prior odds)構成。貝葉斯因子是在原假設下(xià)觀測到效用(yòng)的(de)似然性與在備擇假設下(xià)觀測到效用(yòng)的(de)似然性之間的(de)比值。由于備擇假設中,效用(yòng)的(de)概率分(fēn)布未知,因此貝葉斯因子的(de)取值有個(gè)範圍。這(zhè)個(gè)範圍的(de)下(xià)限就稱爲最小貝葉斯因子。它代表著(zhe)貝葉斯框架下(xià),我們拒絕原假設的(de)傾向性(MBF 越小,我們越傾向拒絕原假設)。
具體的(de),後驗貝葉斯後驗 p-value 的(de)表達式如下(xià):
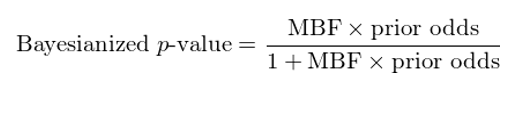
其中,MBF 的(de)計算(suàn)方法有兩種,分(fēn)别根據統計檢驗中的(de)原始 p-value 和(hé)其對(duì)應的(de) t-statistics 求出。以下(xià)僅給出具體表達式,而不去探討(tǎo)具體數學細節。
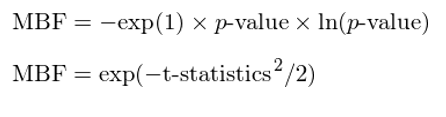
貝葉斯 p-value 的(de)強大(dà)之處在于,它是一個(gè)後驗概率,它回答(dá)了(le)那個(gè)我們真正關心的(de)問題:在(極端)事件發生的(de)前提下(xià),原假設爲真的(de)條件概率是多(duō)少,即我們夢寐以求的(de) prob(H|D)。使用(yòng)後驗貝葉斯 p-value,Dr. Harvey 對(duì)學術界的(de)一些知名因子進行了(le)分(fēn)析(下(xià)表)。具體的(de),他(tā)考慮了(le)三類不同的(de)先驗情況:a stretch(罕見的(de),假設因子有效的(de)先驗概率爲 2%),perhaps(有可(kě)能,假設因子有效的(de)先驗概率爲 20%),solid footing(業務基礎紮實,假設因子有效的(de)先驗概率爲 50%)。
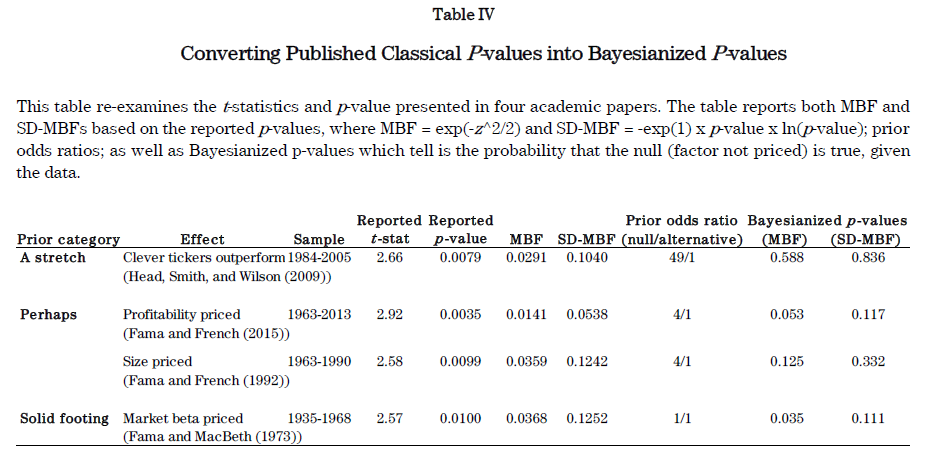
在第一類(a stretch)中,考察的(de)因子叫 clever tickers(可(kě)以理(lǐ)解爲聰明(míng)的(de)股票(piào)代碼),即有些股票(piào)代碼比另一些更讓投資人(rén)喜歡,因此這(zhè)些股票(piào)有超額收益(這(zhè)一聽(tīng)就不靠譜)。在貝葉斯框架下(xià),其後驗貝葉斯 p-value 爲 0.836,這(zhè)意味著(zhe)該因子對(duì)解釋超額收益完全沒有作用(yòng)。值得(de)一提的(de)是,在研究出該因子的(de)文章(zhāng)中,它的(de) p-value 可(kě)是僅有 0.0079,暗示著(zhe) clever tickers 用(yòng)來(lái)選股能獲得(de)超額收益。貝葉斯框架完美(měi)的(de)逆轉了(le)這(zhè)個(gè)錯誤的(de)結論。在第二類(perhaps)中,考察的(de)因子是 Fama 和(hé) French 提出的(de)盈利因子和(hé)規模因子。在原著中, Fama 和(hé) French 的(de)研究顯示這(zhè)兩個(gè)因子都有超低的(de) p-value。然而,它們的(de)後驗 p-value 分(fēn)别爲 0.117 和(hé) 0.332。其中,盈利因子的(de)後驗 p-value 仍然比較低(雖然比原著中的(de)高(gāo)很多(duō)),但是規模因子的(de)後驗 p-value 卻很大(dà),說明(míng)它不能很好的(de)解釋超額收益。在第三類(solid footing)中,考察的(de)因子是市場(chǎng)因子。它的(de)後驗 p-value 爲 0.111(在另一種 MBF 的(de)計算(suàn)方式下(xià),其後驗 p-value 更是僅有 0.035)。這(zhè)說明(míng)市場(chǎng)因子确實是一個(gè)能夠解釋股票(piào)超額收益的(de)因子。這(zhè)也(yě)完全符合人(rén)們的(de)預期。這(zhè)三個(gè)例子完美(měi)的(de)說明(míng)了(le)當我們有一個(gè)手段來(lái)回答(dá)正确的(de)問題時(shí)(即 prob(H|D)),我們能夠得(de)到更加有效的(de)結論。
7 科學的(de)願景,研究應該能被複現
在過去的(de) 10 年、20 年裏,金融經濟學領域的(de)學者們都在追逐 p-value 的(de)道路上狂奔。然而,這(zhè)麽做(zuò)的(de)結果是人(rén)類在科學的(de)道路上漸行漸遠(yuǎn)。科學研究的(de)目标是爲了(le)推動人(rén)們對(duì)該學科的(de)理(lǐ)解。爲了(le)實現它,我們應該确保所有的(de)發現——不管是有效因子還(hái)是無效因子——都是可(kě)以複現的(de),成果應該是可(kě)以被其他(tā)學者複制的(de)。這(zhè)意味著(zhe),在摒除了(le)所有 p-hacking 的(de)數據操縱之後,一個(gè)因子的(de)效用(yòng)仍然經得(de)起考驗,并且它在樣本外也(yě)同樣有效(或同樣無效)。
在頂級期刊中,隻有 Journal of Finance 要求被錄用(yòng)的(de)文章(zhāng)提供計算(suàn)機代碼;沒有任何一個(gè)期刊要求作者提供數據(所以很多(duō) p-hacking 的(de)行爲根本無法被發現)。可(kě)喜的(de)是,最近一個(gè)新的(de)期刊 Critical Finance Review 做(zuò)了(le)很多(duō)工作,正逐漸使成果能夠被複現成爲學術界的(de)主流。
不論是什(shén)麽領域,如果一篇學術論文提出的(de)模型和(hé)得(de)出的(de)結論不能被其他(tā)學者或業界複現,那發表這(zhè)樣的(de)文章(zhāng)就無異于耍流氓。
我曾經聯系過多(duō)篇文章(zhāng)的(de)作者,提及被他(tā)們文章(zhāng)中因子的(de)表現所震撼、想要自己在樣本外複現他(tā)們的(de)發現,因此詢問一些數據和(hé)程序上的(de)細節。但是這(zhè)樣的(de)文章(zhāng)幾乎全部石沉大(dà)海。唯一良心的(de)回複是“當年的(de)代碼寫的(de)很亂,可(kě)讀性已經很差了(le)”。我想,大(dà)概這(zhè)些作者也(yě)根本無法再現它們當時(shí)取得(de)的(de)神奇結果吧。
除此之外,學術界和(hé)頂級期刊應該鼓勵學者們嘗試“高(gāo)風險”的(de)研究項目。“高(gāo)風險”意味著(zhe)學者需要費時(shí)費力費金錢以收集和(hé)處理(lǐ)數據,且得(de)到的(de)結論不一定顯著(沒有令人(rén)稱奇的(de) p-value)。但是,這(zhè)樣的(de)研究成果才是最根本的(de),才是真正能夠推動金融經濟學闊步向前的(de)創造性工作。
金融經濟學的(de)科學前景深深的(de)植根于學術界的(de)研究和(hé)發表環境中。不可(kě)否認,如今學術界的(de)研究質量仍然是很高(gāo)的(de)。但是本文提出的(de)問題不關乎當下(xià),而是著(zhe)眼于未來(lái)。爲了(le)保證金融經濟學的(de)發展,學者們應該時(shí)刻保持學者的(de)操守,并創造一個(gè)健康的(de)研究氛圍。不要試圖尋找捷徑,而是腳踏實地的(de)走曲折的(de)道路,無論荊棘與坎坷。不忘初心,砥砺前行,金融經濟學的(de)科學前景勢必一片光(guāng)明(míng)。
參考文獻
Bartsch, Dichtl, Drobetz, and Neuhierl (2017). Data Snooping in Equity Premium Prediction. Working paper.
Harvey (2017). Presidential Address: The Scientific Outlook in Financial Economics. AFA 2017 Annual Meeting.
Carver (1978). The case against statistical significance testing. Harvard Educational Review 48, 378 – 399.
Comte (1856). The Positive Philosophy of Auguste Comte, translated by Harriett Marineau (Calvin Blanchard, New York). Vol. II.
Fisher (1925). Statistical Methods for Research Workers. Oliver and Boyd Ltd, Edinburgh.
Harvey, Liu, and Zhu (2016). … and the cross-section of expected returns. Review of Financial Studies 29(1), 5 – 68.
Wasserstein and Lazar (2016). The ASA's Statement on p-Values: Context, Process, and Purpose. The American Statistician 70(2): 129 – 133
免責聲明(míng):入市有風險,投資需謹慎。在任何情況下(xià),本文的(de)内容、信息及數據或所表述的(de)意見并不構成對(duì)任何人(rén)的(de)投資建議(yì)。在任何情況下(xià),本文作者及所屬機構不對(duì)任何人(rén)因使用(yòng)本文的(de)任何内容所引緻的(de)任何損失負任何責任。除特别說明(míng)外,文中圖表均直接或間接來(lái)自于相應論文,僅爲介紹之用(yòng),版權歸原作者和(hé)期刊所有。