
Anomalies, Factors, and Multi-Factor Models
發布時(shí)間:2019-02-13 | 來(lái)源: 川總寫量化(huà)
作者:石川
摘要:本文解釋了(le)異象、因子以及多(duō)因子模型的(de)區(qū)别和(hé)聯系;梳理(lǐ)了(le)從異象到因子再到模型背後的(de)邏輯;介紹了(le)學術界研究多(duō)因子模型的(de)主流統計手段。
1 引言
在 empirical asset pricing 和(hé) factor investing 中,anomalies(異象)、factors(因子)以及 multi-factor models(多(duō)因子模型)是三個(gè)常見的(de)概念。從這(zhè)些概念出發又能很自然的(de)引發出一系列問題:
1. 什(shén)麽是 anomalies;什(shén)麽是 factors?
2. Anomalies 和(hé) factors 有什(shén)麽區(qū)别?
3. 一個(gè) multi-factor model 中應該包含多(duō)少個(gè) factors?
4. 學術界有哪些主流的(de) multi-factor models?
5. 如何比較并在不同的(de) multi-factor models 之間取舍?
在過去幾十年裏,海外學術界對(duì)上述問題進行了(le)大(dà)量的(de)探索,留下(xià)了(le)很多(duō)寶貴的(de)實證結果和(hé)分(fēn)析手段。而對(duì)于像你、我一樣進行因子投資的(de)投資者來(lái)說,搞清楚這(zhè)些問題對(duì)于構建系統和(hé)全面的(de)因子投資分(fēn)析體系至關重要。本文試圖回答(dá)上述五個(gè)問題。
2 Anomalies
多(duō)因子模型是 empirical asset pricing 的(de)一種常見方法;其研究的(de)核心問題是找到一組能夠解釋股票(piào)預期收益率截面差異的(de)因子(見《股票(piào)多(duō)因子模型的(de)回歸檢驗》)。假使我們根據基本面特征或量價指标(或 whatever,下(xià)面統稱爲特征)挑選出一攬子股票(piào)并構建多(duō)空投資組合;如果該組合的(de)收益率無法被用(yòng)于 asset pricing 的(de)多(duō)因子模型解釋,則稱該特征爲一個(gè)異象(anomaly)。在數學上,這(zhè)意味著(zhe)該組合有模型無法解釋的(de) α 收益率:以使用(yòng)該特征構建的(de)多(duō)空組合收益率爲被解釋變量放在回歸方程的(de)左側,以多(duō)因子模型中因子收益率爲解釋變量放在回歸方程的(de)右邊,進行時(shí)序回歸,回歸的(de)截距項就是 α 收益率;如果 α 顯著不爲零,則說明(míng)該特征是一個(gè)異象。
舉個(gè)例子。《獲取 α 的(de)新思路:科技關聯度》一文介紹了(le) Lee et al. (2018) 這(zhè)篇文章(zhāng);使用(yòng)科技關聯度選股的(de)多(duō)空對(duì)沖投資組合獲得(de)了(le)主流多(duō)因子模型無法解釋的(de) α 收益率(下(xià)圖),因此它是一個(gè)異象。

從有效市場(chǎng)假說的(de)觀點出發,市場(chǎng)中不應該存在很多(duō)異象。當然,有效市場(chǎng)假說并不完美(měi),再加上學術界幾十年來(lái)的(de)“不懈努力”,針對(duì)美(měi)股挖掘出了(le) 400+ 個(gè)異象,這(zhè)些異象在樣本内的(de)統計檢驗中都獲得(de)了(le)很高(gāo)的(de) t-statistics。産生如此多(duō)的(de)異象主要有兩個(gè)原因:
第一個(gè)也(yě)是最主要的(de)一個(gè)原因是數據挖掘。在 p-hacking 的(de)激勵和(hé)多(duō)重假設檢驗的(de)盛行下(xià),大(dà)量所謂的(de)異象在樣本内被挖出。Harvey, Liu and Zhu (2016) 研究了(le)學術界發表的(de) 316 個(gè)所謂顯著異象,并指出再考慮了(le) multiple testing 的(de)影(yǐng)響後,異象收益率的(de) t-statistic 至少要超過 3.0(而非人(rén)們傳統認爲的(de) 5% 的(de)顯著性水(shuǐ)平對(duì)應的(de) 2.0)才有可(kě)能是真正有效、而非來(lái)自運氣。
第二個(gè)原因和(hé)回歸方程右側的(de)定價模型有關。比如,如果僅以 CAPM 爲定價模型,那麽很多(duō)異象都能獲得(de) CAPM 無法解釋的(de) α 收益率;随著(zhe)定價模型中因子個(gè)數的(de)增加,更多(duō)的(de)異象變得(de)不再顯著。然而,真正的(de)定價模型是未知的(de)。
談及對(duì)異象的(de)研究,不能不提的(de)一篇文章(zhāng)是 Hou, Xue and Zhang (2017)。這(zhè)篇長(cháng)達 146 頁的(de)文章(zhāng)驚人(rén)的(de)複現了(le)學術界提出的(de) 447 個(gè)異象,涵蓋動量(57個(gè))、價值/成長(cháng)(68個(gè))、投資(38個(gè))、盈利(79個(gè))、無形資産(103個(gè))、以及交易摩擦(102個(gè))六大(dà)類。下(xià)圖節選了(le)少量動量類異象說明(míng),感受一下(xià)。

對(duì)于這(zhè) 447 個(gè)異象,當排除了(le)微小市值股票(piào)的(de)影(yǐng)響後,其中 286 個(gè)(64%)不再顯著(在 5% 的(de)顯著性水(shuǐ)平下(xià),下(xià)同);如果按照(zhào) Harvey, Liu and Zhu (2016) 的(de)建議(yì)把 t-statistic 阈值提升到 3.0,則其中 380 個(gè)(85%)異象不再顯著;最後,如果使用(yòng) Hou, Xue and Zhang (2015) 提出的(de) 4 因子模型作爲定價模型,那麽其中 436 個(gè)(98%)異象不再顯著,剩餘存活的(de)僅有 11 個(gè)。好一個(gè)數據挖掘!
除此之外,Linnainmaa and Roberts (2018) 花費了(le)很大(dà)的(de)經曆構建了(le)全新的(de)樣本外數據,研究了(le)美(měi)股中源于會計數據的(de) 36 個(gè)異象在樣本内、外的(de)表現的(de)差異。分(fēn)析表明(míng),絕大(dà)部分(fēn)異象在樣本外明(míng)顯失效,它們的(de)失效說明(míng)這(zhè)些異象并非來(lái)自未知風險以及錯誤定價這(zhè)兩種解釋,而更有可(kě)能僅僅是數據挖掘的(de)産物(wù)。
3 Factors
上一節介紹了(le)異象,本節就來(lái)看看什(shén)麽是因子(factors)。一個(gè)異象是可(kě)能成爲一個(gè)優秀因子的(de);然而由于異象之間的(de)相關性,并不是所有異象都是因子。一個(gè)因子應該能夠對(duì)解釋資産(可(kě)以是個(gè)股也(yě)可(kě)以是個(gè)股組成的(de)投資組合)預期收益率的(de)截面差異有顯著的(de)增量貢獻。如果異象滿足上述條件,它就可(kě)以被稱之爲一個(gè)因子。在這(zhè)個(gè)定義中,有兩個(gè)關鍵詞值得(de)解讀,它們是“解釋”和(hé)“增量貢獻”:
1. “解釋”說明(míng)這(zhè)個(gè)異象(或者潛在因子)已經從回歸方程的(de)左側移到了(le)回歸方程的(de)右側,它被用(yòng)來(lái)當作解釋變量來(lái)對(duì)資産的(de)收益率做(zuò)回歸,考察它是否能夠解釋預期收益率的(de)截面差異。
2. “增量貢獻”暗示著(zhe)同時(shí)考慮多(duō)個(gè)異象(因子)時(shí),由于它們之間不完全獨立,需要排除相關性的(de)影(yǐng)響。
舉個(gè)例子。我們知道價值因子是一個(gè)靠譜的(de)選股因子。然而,很多(duō)指标 —— 比如 E/P 或 B/P 都可(kě)以用(yòng)來(lái)構建價值因子的(de) High-Minus-Low 組合。如果同時(shí)基于 E/P 和(hé) B/P 構建了(le) HML_EP 和(hé) HML_BP 兩個(gè)因子,它們之間的(de)相關性注定是非常高(gāo)的(de)。一旦選擇了(le)其中之一作爲價值因子,另一個(gè)對(duì)于資産預期收益率截面差異解釋能力的(de)增量貢獻就不再顯著、無法成爲因子。從資産定價的(de)理(lǐ)論角度來(lái)說,多(duō)因子模型中的(de)因子之間應盡可(kě)能獨立;但是從投資實踐來(lái)說,上面例子中的(de) E/P 和(hé) B/P 可(kě)以被同時(shí)使用(yòng)構建一個(gè) HML 價值因子,這(zhè)有助于降低波動且增加因子的(de)魯棒性。
在從一攬子異象中篩選因子時(shí),常見的(de)做(zuò)法是将它們同時(shí)作爲回歸分(fēn)析中的(de)解釋變量,采用(yòng) Fama-MacBeth Regression(Fama and MacBeth 1973)來(lái)分(fēn)析這(zhè)些異象的(de)收益率是否顯著。在這(zhè)方面,Green, Hand and Zhang (2017) 是一個(gè)很好的(de)例子。Green, Hand and Zhang (2017) 使用(yòng) Fama-MacBeth Regression 同時(shí)檢驗 94 個(gè)異象,并考慮了(le) multiple testing 對(duì) t-statistic 以及 p-value 造成的(de)影(yǐng)響,最終發現僅有 12 個(gè)異象可(kě)能成爲潛在的(de)因子:1. 賬面市值比;2. 現金;3. 分(fēn)析師數量的(de)變化(huà);4. 盈餘公告宣告收益;5. 一個(gè)月(yuè)的(de)動量;6. 六個(gè)月(yuè)動量的(de)變化(huà);7. 盈利同比增長(cháng)的(de)季度數量;8. 年度研發支出占市值的(de)比重;9. 收益波動性;10. 股票(piào)換手率;11. 股票(piào)換手率的(de)波動性;12. 零交易的(de)天數。上述結果告訴我們:在修正 multiple testing 的(de)數據挖掘、以及考察了(le)不同異象的(de)相關性之後,真正能夠解釋資産預期收益率截面差異的(de)獨立因子少之又少。
4 Multi-Factor Models
現在我們已經了(le)解了(le)異象,并通(tōng)過回歸分(fēn)析從異象中找出了(le)因子,接下(xià)來(lái)就是挑選因子構建多(duō)因子模型了(le)。在構建多(duō)因子模型時(shí),兩個(gè)必須要回答(dá)的(de)問題是:(1)選擇多(duō)少個(gè)因子合适?(2)選擇哪些因子更好?學術界對(duì)于第一個(gè)問題的(de)共識爲主流因子模型奠定了(le)基調;而第二個(gè)問題則涉及不同多(duō)因子模型之間的(de)比較。對(duì)于第一個(gè)問題,我們總可(kě)以僅使用(yòng)一個(gè)因子,比如 CAPM 模型僅使用(yòng)了(le)市場(chǎng)因子;又或者我們可(kě)以使用(yòng)許多(duō)因子。一個(gè)極端的(de)情況是把每個(gè)上市公司作爲一個(gè)因子,每個(gè)公司的(de)股票(piào)隻在自己公司的(de)因子上有暴露,在代表其他(tā)公司的(de)因子上零暴露。這(zhè)樣的(de)模型顯然能完美(měi)解釋股票(piào)預期收益率的(de)截面差異,但在現實中沒人(rén)會那麽用(yòng)。以樣本内過拟合爲代價,更多(duō)的(de)因子總能更好的(de)解釋收益率的(de)截面差異。
在學術界,“幾個(gè)因子合适”這(zhè)個(gè)問題所遵循的(de)準則是 The Law of Parsimony(簡約法則),它還(hái)有一個(gè)更爲人(rén)熟知的(de)名字 —— Occam’s razor(奧卡姆剃刀(dāo))。如果從 ICAPM(Intertemporal CAPM)的(de)角度來(lái)理(lǐ)解多(duō)因子模型,每個(gè)因子代表某種 state variable;而 state variable 是投資者想要對(duì)沖的(de)某種風險。從這(zhè)個(gè)意義上說,因子的(de)個(gè)數應該是有限的(de)。依據簡約法則,學術界主流的(de)多(duō)因子模型包括以下(xià)幾個(gè)(按時(shí)間順序、排名不分(fēn)先後,不完整 list),它們的(de)因子個(gè)數均在 3 到 5 個(gè)之間:
Fama-French 三因子模型(Fama and French 1993):多(duō)因子模型的(de)開山鼻祖,包括 MKT,HML 以及 SMB 三因子。
Carhart 四因子模型(Carhart 1997):在 Fama-French 三因子模型上加上了(le)動量 MOM 因子。
Novy-Marx 四因子模型(Novy-Marx 2013):包含 MKT,HML,MOM 以及 PMU 四個(gè)因子;其中 PMU 所用(yòng)的(de)财務指标是 Gross Profit-to-Asset,代表 profitability 維度。
Fama-French 五因子模型(Fama and French 2015):Fama 和(hé) French 在其三因子模型的(de)基礎上加入了(le) CMA 和(hé) RMW 兩個(gè)因子,分(fēn)别代表 investment 和(hé) profitability 兩個(gè)維度。
Hou-Xue-Zhang 四因子模型(Hou, Xue and Zhang 2015):包含 MKT,SMB,IVA 以及 ROE;其中 IVA 是 total assets 的(de)年增長(cháng)率,代表 investment 維度。
Stambaugh-Yuan 四因子模型(Stambaugh and Yuan 2016):包含 MKT,SMB,MGMT 和(hé) PERF 四個(gè)因子。MGMT 和(hé) PERF 分(fēn)别使用(yòng)了(le) 6 個(gè)和(hé) 5 個(gè)指标,代表和(hé) management 以及 performance 相關的(de)兩個(gè) mispricing 因子。雖然該模型隻有四個(gè)因子,但它用(yòng)到的(de)基本面和(hé)量價指标多(duō)達 12 個(gè)。
Daniel-Hirshleifer-Sun 三因子模型(Daniel, Hirshleifer and Sun 2018):在 MKT 的(de)基礎上,使用(yòng) PEAD 和(hé) FIN 兩個(gè)指标作爲短期和(hé)長(cháng)期行爲因子(behavioral factors)的(de)代理(lǐ)指标,構建了(le)三因子模型。該模型由于包括了(le)傳統的(de) MKT 風險因子,又包括行爲因子,故稱爲複合模型。
如何比較不同的(de)多(duō)因子模型呢(ne)?學術界主要有以下(xià)三種方法:
1. GRS tests;
2. Mean-Variance Spanning tests;
3. Bayesian approach。
GRS tests(Gibbons, Ross and Shanken 1989)檢驗 n 個(gè)資産在給定因子模型下(xià)的(de)定價錯誤(pricing error)—— 即 α —— 是否在統計上聯合爲零(jointly equal to zero)。在比較兩個(gè)多(duō)因子模型時(shí),使用(yòng)兩個(gè)模型的(de)因子互爲資産和(hé)定價模型進行檢驗。舉個(gè)例子。《中國版的(de) Fama-French 三因子模型,了(le)解一下(xià)?》一文中比較了(le)兩個(gè)不同版本的(de)價值和(hé)市值因子的(de)效果。結果(下(xià)表)顯示,當使用(yòng) SMB 和(hé) VMG 爲因子模型時(shí),FFSMB 和(hé) FFHML 的(de)定價錯誤可(kě)以認爲是零(p-value = 0.41);反過來(lái),當使用(yòng) FFSMB 和(hé) FFHML 爲定價模型時(shí),SMB 和(hé) VMG 依然存在顯著不爲零的(de)定價錯誤(p-value 是 10 的(de) -13 次方這(zhè)個(gè)量級)。這(zhè)意味著(zhe) SMB 和(hé) VMG 優于 FFSMB 和(hé) FFHML。

Mean-Variance Spanning tests 考察 n 個(gè)已知資産構建的(de) mean-variance 有效前沿能否包含某個(gè)新資産(Huberman and Kandel 1987)。在比較兩個(gè)多(duō)因子模型時(shí),使用(yòng)每個(gè)模型的(de)因子構建有效前沿,并逐一檢驗其能否包含另一個(gè)模型中的(de)因子。舉個(gè)例子。《美(měi)股上一個(gè)跨越時(shí)間尺度的(de)趨勢因子》介紹了(le)一個(gè)新的(de)趨勢因子。考慮新的(de)趨勢因子和(hé)三個(gè)已有因子(SREV、MOM 以及 LREV)的(de)回歸模型如下(xià):
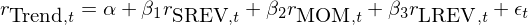
該檢驗的(de) null hypothesis 是:
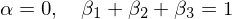
檢驗結果顯著的(de)拒絕原假設,說明(míng)已有三因子無法解釋新的(de)趨勢因子。最後來(lái)看看 Bayesian approach。假設比較兩個(gè)多(duō)因子模型 M_1 和(hé) M_2;相關數據集用(yòng) D 表示。令 prob(M_1) 和(hé) prob(M_2) 爲這(zhè)兩個(gè)模型的(de)先驗概率,且有 prob(M_1) + prob(M_2) = 1(這(zhè)裏假設把多(duō)個(gè)模型兩兩比較)。根據貝葉斯定理(lǐ)有:
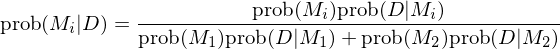
其中:
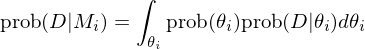
上式中,prob(θ_i) 是模型 i 參數的(de)先驗分(fēn)布,prob(D|θ_i) 是模型 i 的(de)似然函數。上述貝葉斯方法的(de)核心在于确定 prob(θ_i)。根據 Pastor and Stambaugh (2000) 以及 Barillas and Shanken (2018) 的(de)理(lǐ)論,它和(hé)以兩個(gè)模型中的(de)全部因子作爲資産所構成的(de)投資組合的(de)預期最大(dà)夏普率的(de)平方與市場(chǎng)夏普率的(de)比值有關。使用(yòng)貝葉斯方法,Stambaugh and Yuan (2016) 比較了(le)他(tā)們的(de)四因子模型(記爲 M-4)和(hé) Fama-French 五因子模型(記爲 FF-5)以及 Hou-Xue-Zhang 四因子模型(記爲 q-4)。下(xià)圖中,左圖是 M-4 和(hé) FF-5 模型的(de)比較;右圖是 M-4 和(hé) q-4 模型的(de)比較。圖中,橫坐(zuò)标均爲先驗,即兩模型中全部因子能達到的(de)最大(dà)預期夏普率平方和(hé)市場(chǎng)夏普率的(de)比值;縱坐(zuò)标爲不同模型的(de)後驗概率。

結果說明(míng),當先驗這(zhè)個(gè)比值分(fēn)别大(dà)于 1.05 和(hé) 1.2 的(de)時(shí)候,M-4 因子模型就分(fēn)别強于 FF-5 和(hé) q-4 模型。顯然,使用(yòng)多(duō)個(gè)因子得(de)到的(de)最大(dà)夏普率很容易是市場(chǎng)夏普率的(de) 1.05 或 1.2 倍,意味著(zhe)數據更加傾向于支持 M-4 模型。需要特别強調的(de)是,無論采用(yòng)哪種方法,比較多(duō)因子模型的(de)目的(de)是爲了(le)得(de)到新的(de)啓發,而非一定要排個(gè)一二三四。這(zhè)些因子模型之間孰優孰劣并無定論,它們的(de)提出豐富了(le)我們對(duì)于 empirical asset pricing 的(de)理(lǐ)解并指導著(zhe)因子投資。
5 模型複雜(zá)度討(tǎo)論
在結束本文之前,再來(lái)簡單討(tǎo)論下(xià)構建因子模型時(shí)遵循的(de) The Law of Parsimony。在美(měi)國金融協會 2018 年的(de)年會上,Daniel, Hirshleifer and Sun (2018) 報告了(le)他(tā)們的(de)複合因子模型,并對(duì)模型複雜(zá)度和(hé)模型的(de)解釋效果做(zuò)了(le)探討(tǎo),頗有新意。具體的(de),他(tā)們提出了(le)兩個(gè) Parsimony Index,通(tōng)過懲罰因子和(hé)用(yòng)于構建因子的(de)指标個(gè)數來(lái)計算(suàn)模型複雜(zá)度。
第一個(gè) Parsimony Index = 零減去模型中所有因子使用(yòng)的(de)全部指标數之和(hé);由此可(kě)知該 index 取值爲負,越大(dà)(即越接近零)說明(míng)模型越簡單。如果一個(gè)指标被用(yòng)于多(duō)個(gè)因子中,則在計算(suàn)該 index 時(shí)需要多(duō)次計算(suàn)它。
第二個(gè) Parsimony Index = 零減去模型中的(de)因子和(hé)指标個(gè)數之和(hé);同上,該 index 取值爲負,越大(dà)(即越接近零)說明(míng)模型越簡單。它和(hé)前者的(de)區(qū)别爲:(1)除指标外,也(yě)考慮了(le)對(duì)因子個(gè)數的(de)懲罰;(2)如果某指标被用(yòng)于多(duō)個(gè)因子中,其隻被計算(suàn)一次。
按照(zhào)上述定義,本文第四節介紹的(de)主流因子模型的(de)兩個(gè) Parsimony Index 取值分(fēn)别爲:

使用(yòng)上述 7 個(gè)因子模型來(lái)檢驗 34 個(gè)異象,根據 5% 顯著性水(shuǐ)平下(xià)顯著的(de)異象的(de)個(gè)數以及所有異象的(de)平均 α 收益率的(de)絕對(duì)值分(fēn)别作爲模型解釋力度,最後将模型解釋力度和(hé)這(zhè)兩個(gè) Parsimony Index 分(fēn)别做(zuò)回歸以觀察解釋度和(hé)模型複雜(zá)度之間的(de)關系。結果如下(xià)。以 5% 顯著性水(shuǐ)平的(de)異象個(gè)數作爲解釋力度:

以全部異象平均 |α| 爲解釋力度:

随著(zhe)模型複雜(zá)度的(de)提升(表現爲 Parsimony Index 的(de)取值更小),模型的(de)解釋力度上升(體現爲 5% 顯著性下(xià)的(de)異象變少和(hé)異象平均 |α| 降低)。這(zhè)個(gè)結論符合預期,它也(yě)再次強調了(le)不同因子模型之間的(de)好壞并無定論 —— 我們總能通(tōng)過增加模型複雜(zá)度來(lái)提升模型(樣本内)的(de)解釋效果,因此需要在模型複雜(zá)度和(hé)樣本内的(de)解釋力度之間取舍。在 The Law of Parsimony 的(de)指導思想下(xià),一個(gè)優秀的(de)因子模型通(tōng)常有較少的(de)因子或者基本面或量價特征;而作爲使用(yòng)者,我們應該盡量搞清楚每一個(gè)因子背後代表的(de)風險。
6 結語
這(zhè)篇文章(zhāng)沒有告訴你哪個(gè)異象能賺取 α。這(zhè)篇文章(zhāng)沒有告訴你哪個(gè)因子能賺取高(gāo)性價比的(de) β。這(zhè)篇文章(zhāng)也(yě)沒有告訴你哪家的(de)多(duō)因子模型更勝一籌。
OK, enough for “自我否定”。既然如此,爲什(shén)麽要寫這(zhè)篇文章(zhāng)呢(ne)?如今,學術論文和(hé)賣方報告中開發出新“因子”的(de)速度已遠(yuǎn)超我能理(lǐ)解、消化(huà)的(de)速度。以學術界的(de) 447 個(gè)異象爲例,如果每周寫一篇介紹一個(gè),要寫 9 年。異象被當作“因子”來(lái)使用(yòng),但它背後往往沒有合理(lǐ)的(de)金融學解釋(即無法代表合理(lǐ)的(de)系統性風險),或者沒有用(yòng)已有因子對(duì)其分(fēn)析從而評判它對(duì)解釋股票(piào)預期收益率截面差異的(de)增量貢獻,僅僅是數據挖掘的(de)産物(wù)。它們中大(dà)多(duō)數根本不是因子,甚至連異象都談不上。出于這(zhè)個(gè)原因,我希望能介紹一些方法,幫助因子投資的(de)踐行者去僞存真。這(zhè)就是寫作本文的(de)初衷。
這(zhè)篇文章(zhāng)回答(dá)了(le)開篇提出的(de)五個(gè)問題;解釋了(le)異象、因子以及多(duō)因子模型的(de)區(qū)别和(hé)聯系;梳理(lǐ)了(le)從異象到因子再到模型,一步步使用(yòng)多(duō)因子模型背後的(de)邏輯;介紹了(le)學術界在研究多(duō)因子時(shí)使用(yòng)的(de)主流統計手段。希望它能夠作爲一個(gè)完善的(de)工具箱,爲你的(de)多(duō)因子研究和(hé)投資添一分(fēn)助力。
參考文獻
Barillas, F. and J. Shanken (2018). Comparing asset pricing models. Journal of Finance 73(2), 715 – 754.
Carhart, M. M. (1997). On persistence in mutual fund performance. Journal of Finance 52(1), 57 – 82.
Daniel, K. D., D. A. Hirshleifer and L. Sun (2018). Short- and long-horizon behavioral factors. Columbia Business School Research Paper No. 18-5.
Fama, E. F. and K. R. French (1993). Common risk factors in the returns on stocks and bonds. Journal of Financial Economics 33(1), 3 – 56.
Fama, E. F. and K. R. French (2015). A five-factor asset pricing model. Journal of Financial Economics 116(1), 1 – 22.
Fama, E. F. and J. D. MacBeth (1973). Risk, return, and equilibrium: Empirical tests. Journal of Political Economy 81(3), 607 – 636.
Green, J., J. R. M. Hand and X. F. Zhang (2017). The characteristics that provide independent information about average U.S. monthly stock returns. Review of Financial Studies 30(12), 4389 – 4436.
Gibbons, M. R., S. A. Ross and J. Shanken (1989). A test of the efficiency of a given portfolio. Econometrica 57(5), 1121 – 1152.
Harvey, C. R., Y. Liu and H. Zhu (2016). … and the cross-section of expected returns. Review of Financial Studies 29(1), 5 – 68.
Hou, K., C. Xue and L. Zhang (2015). Digesting anomalies: An investment approach. Review of Financial Studies 28(3), 650 – 705.
Hou, K., C. Xue and L. Zhang (2017). Replicating Anomalies. Fisher College of Business Working Paper No. 2017-03-010; Charles A. Dice Center Working Paper No. 2017-10.
Huberman G. and S. Kandel (1987). Mean-variance spanning. Journal of Finance 42(4), 873 – 888.
Lee, C. M. C., S. T. Sun, R. Wang and R. Zhang (2018). Technological Links and Return Predictability. Journal of Financial Economics forthcoming.
Linnainmaa, J. T. and M. R. Roberts (2018). The history of the cross-section of stock returns. Review of Financial Studies 31(7), 2606 – 2649.
Liu, J., R. F. Stambaugh and Y. Yuan (2018). Size and Value in China. Journal of Financial Economics forthcoming.
Novy-Marx, R. (2013). The other side of value: The gross profitability premium. Journal of Financial Economics 108(1), 1 – 28.
Pastor, L. and R. F. Stambaugh (2000). Comparing asset pricing models: an investment perspective. Journal of Financial Economics 56(3), 335 – 381.
Stambaugh, R. F. and Y. Yuan (2016). Mispricing Factors. Review of Financial Studies 30(4), 1270 – 1315.
免責聲明(míng):入市有風險,投資需謹慎。在任何情況下(xià),本文的(de)内容、信息及數據或所表述的(de)意見并不構成對(duì)任何人(rén)的(de)投資建議(yì)。在任何情況下(xià),本文作者及所屬機構不對(duì)任何人(rén)因使用(yòng)本文的(de)任何内容所引緻的(de)任何損失負任何責任。除特别說明(míng)外,文中圖表均直接或間接來(lái)自于相應論文,僅爲介紹之用(yòng),版權歸原作者和(hé)期刊所有。