
監督學習(xí)算(suàn)法中的(de)偏差 — 方差困境
發布時(shí)間:2017-04-27 | 來(lái)源: 川總寫量化(huà)
作者:石川
摘要:監督學習(xí)的(de)泛化(huà)能力,即預測誤差,是由偏差和(hé)方差(以及殘餘誤差)共同決定。偏差和(hé)方差之間的(de)取舍是一個(gè)永恒的(de)話(huà)題。
1 兩個(gè)醫生
我有兩個(gè)醫生朋友,郭妮荷與安德費婷。她倆都自稱擅長(cháng)新型流感的(de)早期防治,即通(tōng)過分(fēn)析過往臨床患者的(de)體征和(hé)患病與否,她們各自形成一套診斷手段,對(duì)新的(de)就診者進行檢查,判斷其是否患病。然而在診斷手段方面,她倆是截然不同的(de)兩個(gè)極端。
先來(lái)說說這(zhè)位郭大(dà)夫。她要查看患者的(de)三、四十個(gè)指标,既包括常見的(de)血常規、體溫、是否咳嗽、是否頭疼、身高(gāo)、體重等,又包括看似和(hé)診斷毫無關聯的(de),比如飲食習(xí)慣、職業等。結合過去患者的(de)數據,她整理(lǐ)出一些非常奇怪的(de)規律。當新來(lái)的(de)就診者的(de)特定指标滿足她發現的(de)規律後,她便可(kě)以對(duì)這(zhè)名就診者是否感染病毒做(zuò)出判斷。
再來(lái)看看那位安大(dà)夫。與郭大(dà)夫相比,她走的(de)是另一個(gè)極端。憑借她多(duō)年的(de)臨床經驗,她自信僅僅依靠查看體溫以及号脈就能确認就診者是否感染流感。什(shén)麽其他(tā)的(de)血常規或者流感的(de)典型症狀,她一概不看。量量體溫、把把脈,就能告訴你患病與否。
一次,我故意将體溫弄高(gāo),并使得(de)脈搏加快(kuài),然後就去找這(zhè)兩位朋友去了(le)。通(tōng)過将我的(de)體征和(hé)一系列令人(rén)匪夷所思的(de)規律比對(duì),郭大(dà)夫的(de)診斷結果是我沒有得(de)新型流感;而安大(dà)夫通(tōng)過給我量體溫和(hé)号脈,認爲我得(de)了(le)新型流感。翌日,我故技重施,并又去找她們診斷。這(zhè)天,郭大(dà)夫用(yòng)一些新的(de)患者數據更新了(le)她那些所謂的(de)規律。這(zhè)一更新不要緊,面對(duì)和(hé)前一天同樣狀态的(de)我,她竟然給出了(le)我患有新型流感的(de)結論。而安大(dà)夫那邊倒是沒有變化(huà),和(hé)前一日一樣的(de)體溫和(hé)脈搏,她給出同樣的(de)結論。就這(zhè)麽,我反複試了(le)十來(lái)次,幾乎每次從郭大(dà)夫口中都得(de)到不同的(de)診斷結果:時(shí)而說我感染了(le)流感,時(shí)而又說沒有。而安大(dà)夫呢(ne)?結論倒是非常一緻:一直說我患有流感,然而她沒有一次是對(duì)的(de)。
對(duì)于郭大(dà)夫,雖然她在大(dà)部分(fēn)診斷中給出了(le)正确的(de)結論:即我沒有得(de)流感。但是她的(de)診斷結果的(de)變化(huà)(波動)太大(dà),保不齊哪天就診的(de)時(shí)候,我就恰好趕上了(le)她的(de)某個(gè)更新後的(de)規律,就給我診斷爲感染了(le)。而安大(dà)夫呢(ne)?她倒是出奇的(de)一緻,可(kě)是她的(de)結論沒有一次是對(duì)的(de),和(hé)實際情況産生了(le)巨大(dà)的(de)偏差。有了(le)這(zhè)樣的(de)經曆,我對(duì)她倆的(de)診斷手段自然是不敢恭維。
讀到這(zhè)裏,你一定發現了(le)上面這(zhè)個(gè)故事是虛構的(de)。而我的(de)這(zhè)兩位醫生朋友的(de)名字也(yě)隻不過是過拟合(overfitting)和(hé)欠拟合(underfitting)的(de)諧音(yīn)。這(zhè)個(gè)故事描繪了(le)機器學習(xí)領域,監督學習(xí)(supervised learning)建模的(de)一個(gè)典型問題。過往患者的(de)體征是訓練數據的(de)特征(features),這(zhè)些患者是否被确診則是标簽(labels)。這(zhè)兩位大(dà)夫通(tōng)過“學習(xí)”這(zhè)些患者的(de)資料和(hé)診斷結果,總結了(le)自己的(de)診斷手段,這(zhè)個(gè)過程就是建模(modelling)。最終,她們爲我診斷則相當于對(duì)新的(de)數據(訓練集樣本外數據)進行預測(forecasting)。這(zhè)些步驟構成了(le)完整的(de)機器學習(xí)過程。
當監督學習(xí)算(suàn)法建模時(shí),我們會經常遇到上面提到的(de)過拟合或欠拟合的(de)問題。過拟合的(de)模型對(duì)于樣本外數據的(de)預測會有較大(dà)的(de)方差;而欠拟合的(de)模型對(duì)樣本外數據的(de)預測會有較大(dà)的(de)偏差。偏差和(hé)方差就是監督學習(xí)算(suàn)法預測誤差中重要的(de)兩個(gè)組成部分(fēn)(還(hái)有第三個(gè)部分(fēn)是問題固有的(de)殘餘誤差),也(yě)是一對(duì)矛盾的(de)統一體。任何算(suàn)法都必須在偏差和(hé)方差之間取舍。
這(zhè)就是我們今天的(de)話(huà)題。
2 監督學習(xí)模型的(de)泛化(huà)能力
通(tōng)俗的(de)說,監督學習(xí)指的(de)是,使用(yòng)帶有标簽的(de)樣本數據來(lái)訓練一個(gè)機器學習(xí)模型,并用(yòng)這(zhè)個(gè)模型對(duì)新發生的(de)樣本(unseen data)進行定量分(fēn)析。具體的(de),監督學習(xí)包括回歸(regression)和(hé)分(fēn)類(classification)。前者的(de)響應變量一般是一個(gè)連續變量,比如我們可(kě)以構建一個(gè)回歸模型,利用(yòng)過去的(de)價格以及公司基本面數據作爲特征,來(lái)預測股票(piào)的(de)收益率,這(zhè)裏收益率就是一個(gè)連續變量。反觀後者,它的(de)響應變量一般是一個(gè)離散的(de)類别,比如通(tōng)過構建分(fēn)類模型,我們可(kě)以進行垃圾郵件的(de)識别。
當我們把機器學習(xí)應用(yòng)到量化(huà)投資領域時(shí),監督學習(xí)無疑具備廣闊的(de)應用(yòng)前景。然而,就像本文第一節的(de)故事描述的(de)那樣,要想衡量一個(gè)機器學習(xí)模型的(de)效果,必須考察它對(duì)樣本外數據預測的(de)準确性。因爲我們針對(duì)用(yòng)于建模的(de)訓練數據,我們可(kě)以構建出非常精準的(de)模型,但是這(zhè)對(duì)于模型是否對(duì)未來(lái)數據仍然有效毫無意義。一個(gè)好的(de)模型必須對(duì)樣本外數據具備出色的(de)泛化(huà)效果(generalization performance),評價泛化(huà)能力的(de)依據正是模型在樣本外數據的(de)預測誤差。
3 預測誤差的(de)組成
監督學習(xí)模型對(duì)樣本外數據的(de)預測誤差由三部分(fēn)構成:偏差(bias)、方差(variance)、以及固有的(de)殘餘誤差(irreducible error)。殘餘誤差來(lái)自問題本身的(de)随機噪聲(noise),是無法避免的(de)。換句話(huà)說,即便我們知道問題的(de)真實模型,我們的(de)預測仍然會有一定的(de)誤差,該誤差源自問題的(de)随機噪聲,該噪聲帶來(lái)的(de)誤差就是我們預測誤差的(de)下(xià)限。在現實世界中,問題的(de)真實模型是未知的(de),因此我們隻能通(tōng)過已有的(de)樣本數據來(lái)得(de)到真實模型的(de)一個(gè)估計(estimate)。無論我們怎麽估計,估計模型的(de)預測結果和(hé)未知真實模型的(de)預測結果也(yě)總會有差别,這(zhè)便引入了(le)偏差和(hé)方差。
偏差:來(lái)自建模時(shí)對(duì)問題真實模型的(de)錯誤假設(erroneous assumptions)。一個(gè)模型的(de)樣本外預測有很大(dà)的(de)偏差往往意味著(zhe)它沒有有效的(de)發現自變量(特征)和(hé)響應變量(标識)之間的(de)關系;該模型存在欠拟合。
比如我們的(de)安大(dà)夫,如果新型流感可(kě)以通(tōng)過血常規中的(de)某個(gè)血項來(lái)分(fēn)辨,那麽甭管她怎麽量體溫或者号脈,都無法發現這(zhè)個(gè)體征和(hé)是否感染流感的(de)關系。又或者,如果一個(gè)問題的(de)真實模型是非線性的(de),而我們卻用(yòng)了(le)一個(gè)線性模型來(lái)建模,那麽它無論如何也(yě)捕捉不了(le)自變量和(hé)響應變量之間的(de)非線性關系。
方差:源自建模過程中對(duì)訓練集數據變化(huà)的(de)過度敏感(over-sensitivity to training data)。一個(gè)模型的(de)樣本外預測有很高(gāo)的(de)方差意味著(zhe)它發生過拟合:它可(kě)能過度關注自變量和(hé)響應變量之間的(de)非顯著關系,或者錯誤對(duì)随機噪聲建模。
比如我們的(de)郭大(dà)夫過度的(de)關注了(le)幾十個(gè)體征變量,這(zhè)導緻她的(de)診斷對(duì)過往病患的(de)數據非常敏感,以至于在對(duì)新病患預測時(shí),預測結果出現很大(dà)的(de)波動。
4 偏差 — 方差困境
讓我們用(yòng)數學語言來(lái)更精确的(de)解釋偏差和(hé)方差。假設特征變量(通(tōng)常爲一個(gè) n 維向量)爲 x,響應變量爲 y。它們之間的(de)關系由一個(gè)未知的(de)真實函數 f 和(hé)随機噪聲 ε 描述,即:
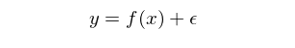
可(kě)見,響應變量 y 和(hé)自變量 x 之間的(de)真實關系爲 f;而 ε 則代表随機噪聲,通(tōng)常被假設爲符合均值爲 0、标準差爲 σ 的(de)正态分(fēn)布。由于 f 未知,我們希望通(tōng)過監督學習(xí),利用(yòng)訓練集樣本數據得(de)到一個(gè) f 的(de)估計,記爲 \hat f。對(duì)于新的(de)數據,利用(yòng)該估計進行預測。
在求解 f 的(de)估計的(de)過程中,機器學習(xí)算(suàn)法看到的(de)僅僅是自變量 x 和(hé)響應變量 y。通(tōng)過考察 x 和(hé) y 的(de)關系,它必須盡可(kě)能的(de)分(fēn)辨出 y 的(de)變化(huà)中,哪部分(fēn)是源自 x 和(hé) y 之間的(de)真正規律(regularities),而哪部分(fēn)是由問題本身的(de)随機噪聲帶來(lái)的(de)。監督學習(xí)模型的(de)樣本外誤差可(kě)以定義爲預測值和(hé)真實值之間的(de)均方誤差(mean squared error),即:
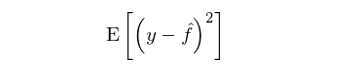
這(zhè)個(gè)誤差可(kě)依下(xià)式分(fēn)解:
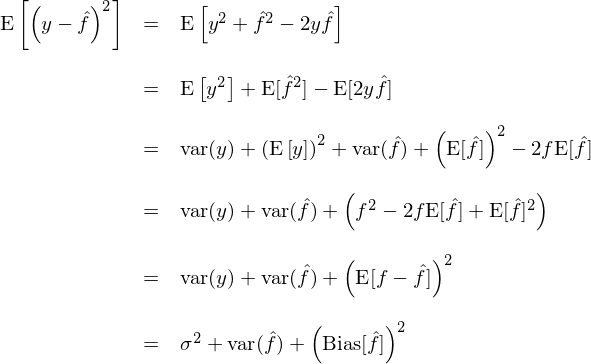
其中,第一項爲問題固有的(de)殘餘誤差,來(lái)自随機噪聲;第二項爲預測的(de)方差;第三項爲預測的(de)偏差(的(de)平方)。需要特别說明(míng)的(de)是,數學期望 E[] 是概率論中的(de)概念,它定義爲一個(gè)随機變量在其概率空間内取值按照(zhào)對(duì)應概率的(de)加權平均值。當數學期望 E[] 應用(yòng)于監督學習(xí)模型在樣本外的(de)預測誤差時(shí),這(zhè)裏的(de)概率空間由自變量 x 和(hé)響應變量 y 的(de)未知聯合分(fēn)布 prob(x, y) 刻畫(huà),取決于未知函數 f 和(hé)随機噪聲 ε;而這(zhè)個(gè)概率空間内的(de)“随機變量的(de)實現”則是一個(gè)個(gè)不同的(de)訓練集,每個(gè)訓練集都是所有曆史數據的(de)一個(gè)子集。由此可(kě)知,這(zhè)裏求解期望的(de)過程時(shí)作用(yòng)于不同的(de)訓練子集上。
對(duì)于一個(gè)給定的(de)模型結構(比如線性模型或者二項式模型),使用(yòng)不同的(de)訓練集訓練便得(de)到模型不同的(de)參數;将使用(yòng)這(zhè)些來(lái)自不同訓練集的(de)模型對(duì)新的(de)樣本點進行預測,得(de)到多(duō)個(gè)預測值。這(zhè)些預測值的(de)平均值和(hé)真實值得(de)差異就是偏差;這(zhè)些預測值之間的(de)差異就是方差:
偏差是“使用(yòng)不同訓練集得(de)到的(de)多(duō)個(gè)模型對(duì)新樣本的(de)響應變量的(de)多(duō)個(gè)預測結果的(de)平均值”與“該新樣本響應變量的(de)真實取值”之間的(de)差異。
方差則衡量“不同的(de)訓練數據集得(de)到的(de)模型對(duì)新樣本的(de)響應變量的(de)多(duō)個(gè)預測結果”之間的(de)差異。
在實際應用(yòng)中,可(kě)以采用(yòng) K 疊交叉驗證(K fold cross-validation)将所有數據分(fēn)爲 K 個(gè)訓練集,以此來(lái)計算(suàn)預測的(de)偏差和(hé)方差。我們會在今後找時(shí)間介紹交叉驗證。
來(lái)看一個(gè)例子。假設真實的(de)函數 f 爲正弦函數 sin,即 y = sin(x) + ε。下(xià)圖中藍色的(de)離散點是由這(zhè)個(gè)過程産生的(de)不同 x 值對(duì)應的(de)響應值;黑(hēi)色曲線代表這(zhè)個(gè)真實函數 f = sin。由于 ε 的(de)存在,藍色的(de)離散點并沒有坐(zuò)落在黑(hēi)色正弦曲線上,而是随機分(fēn)布在黑(hēi)色曲線的(de)上上下(xià)下(xià)。對(duì)于機器學習(xí)來(lái)說,f = sin 是未知的(de),它需要通(tōng)過分(fēn)析這(zhè)些離散點,找到 y 随 x 變化(huà)的(de)真實規律。
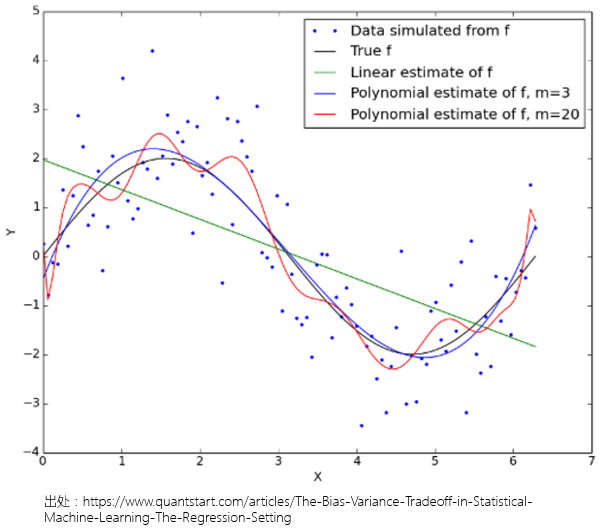
我們基于不同假設産生了(le)三個(gè)複雜(zá)程度不同的(de)模型,作爲對(duì)真實函數 f 的(de)估計:第一個(gè)模型是一個(gè)線性模型(綠色);第二個(gè)模型是一個(gè)三次的(de)多(duō)項式模型(藍色);最後一個(gè)模型是一個(gè)二十次的(de)多(duō)項式模型(紅色)。對(duì)于這(zhè)個(gè)例子,線性關系顯然不是一個(gè)好的(de)模型,它忽視了(le) x 和(hé) y 之間的(de)非線性關系;多(duō)項式模型則能夠捕捉 x 和(hé) y 的(de)關系。
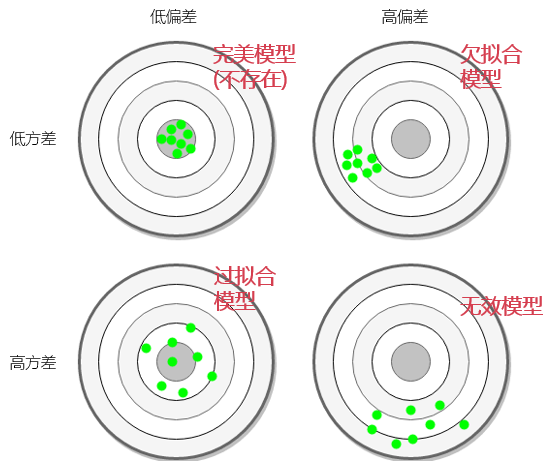
然而,一個(gè)優秀的(de)模型不僅要通(tōng)過訓練集數據正确的(de)發現 x 和(hé) y 的(de)關系,更要對(duì)樣本外數據有優秀的(de)泛化(huà)能力,做(zuò)到低偏差和(hé)低方差。當然,雙低是很難共存的(de)。事實上,偏差和(hé)方差與模型的(de)複雜(zá)度有如下(xià)關系;
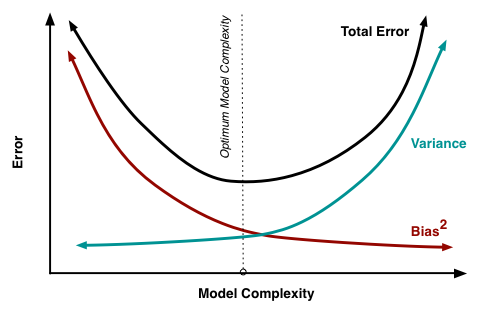
當模型的(de)複雜(zá)度很低時(shí),很容易發生欠拟合,即模型無視了(le) x 和(hé) y 之間的(de)真實關聯,把 y 随 x 的(de)變化(huà)看作是随機誤差。這(zhè)麽做(zuò)雖然使得(de)模型在不同訓練集之間的(de)預測結果方差較小(因爲它根本就沒從這(zhè)些子集中學出來(lái)多(duō)少有效的(de)規律),但是預測均值和(hé)真實值的(de)偏差很大(dà)。随著(zhe)複雜(zá)度的(de)提升,模型可(kě)以越來(lái)越精準的(de)描述訓練集數據,因此模型的(de)偏差越來(lái)越小。然而如果模型過度關注每個(gè)訓練子集中 x 和(hé) y 的(de)片面關系或者噪聲(過拟合),它必将忽視共存于所有訓練子集(即全體曆史數據)中的(de) x 和(hé) y 的(de)重要關系。由此會使得(de)不同訓練集訓練出來(lái)的(de)模型對(duì)新樣本産生不同的(de)預測結果,導緻預測的(de)方差增大(dà)。
在上面這(zhè)個(gè)例子中,二十次多(duō)項式模型雖然有更低的(de)偏差,但是它的(de)方差卻很大(dà)。綜合考慮偏差和(hé)方差,它的(de)預測效果不如三次多(duō)項式模型。事實上,由于在這(zhè)個(gè)假想的(de)例子中,我們知道真實函數 f = sin,可(kě)以看到,三次多(duō)項式模型和(hé)真實的(de) sin 函數非常接近。
總結來(lái)說:
簡單模型,容易欠拟合,方差小,偏差大(dà);
複雜(zá)模型,容易過拟合,偏差小,方差大(dà)。
下(xià)圖是不同模型和(hé)方差以及偏差的(de)關系。注意,這(zhè)僅僅是一個(gè)非常簡化(huà)的(de)示意圖。它似乎說明(míng)如果必須從欠拟合和(hé)過拟合模型選擇,我們應該傾向于欠拟合模型,因爲它的(de)預測結果相對(duì)一緻,我們隻要把它們整體平移一個(gè)偏差值,便可(kě)以得(de)到準确的(de)預測。但是,千萬不要被這(zhè)個(gè)簡單的(de)示意圖誤導,因爲生活中的(de)實際問題遠(yuǎn)遠(yuǎn)比這(zhè)個(gè)圖複雜(zá)的(de)多(duō),我們遠(yuǎn)沒有神之一手來(lái)修正偏差。相反,低偏差高(gāo)方差的(de)模型(假設已經杜絕了(le)過拟合)往往是更有希望的(de)。這(zhè)是因爲可(kě)以利用(yòng)集成學習(xí)元算(suàn)法(ensemble learning meta algorithm)來(lái)降低預測模型的(de)方差,從而提高(gāo)模型的(de)泛化(huà)能力。裝袋算(suàn)法(bagging)、提升算(suàn)法(boosting)、随機森林(lín)(random forest)對(duì)于分(fēn)類樹的(de)改進都是這(zhè)樣的(de)例子。
監督學習(xí)的(de)泛化(huà)能力,即預測誤差,是由偏差和(hé)方差(以及殘餘誤差)共同決定。偏差和(hé)方差之間的(de)取舍是一個(gè)永恒的(de)話(huà)題。在模型的(de)複雜(zá)度和(hé)預測效果之間找到一個(gè)最佳的(de)平衡點,這(zhè)不僅依賴于更先進的(de)機器學習(xí)算(suàn)法不斷的(de)被發現,同時(shí)訓練集的(de)數據質量是否足夠高(gāo)也(yě)至關重要。
過猶不及。
免責聲明(míng):入市有風險,投資需謹慎。在任何情況下(xià),本文的(de)内容、信息及數據或所表述的(de)意見并不構成對(duì)任何人(rén)的(de)投資建議(yì)。在任何情況下(xià),本文作者及所屬機構不對(duì)任何人(rén)因使用(yòng)本文的(de)任何内容所引緻的(de)任何損失負任何責任。除特别說明(míng)外,文中圖表均直接或間接來(lái)自于相應論文,僅爲介紹之用(yòng),版權歸原作者和(hé)期刊所有。